 Few shot prompting
Few shot prompting
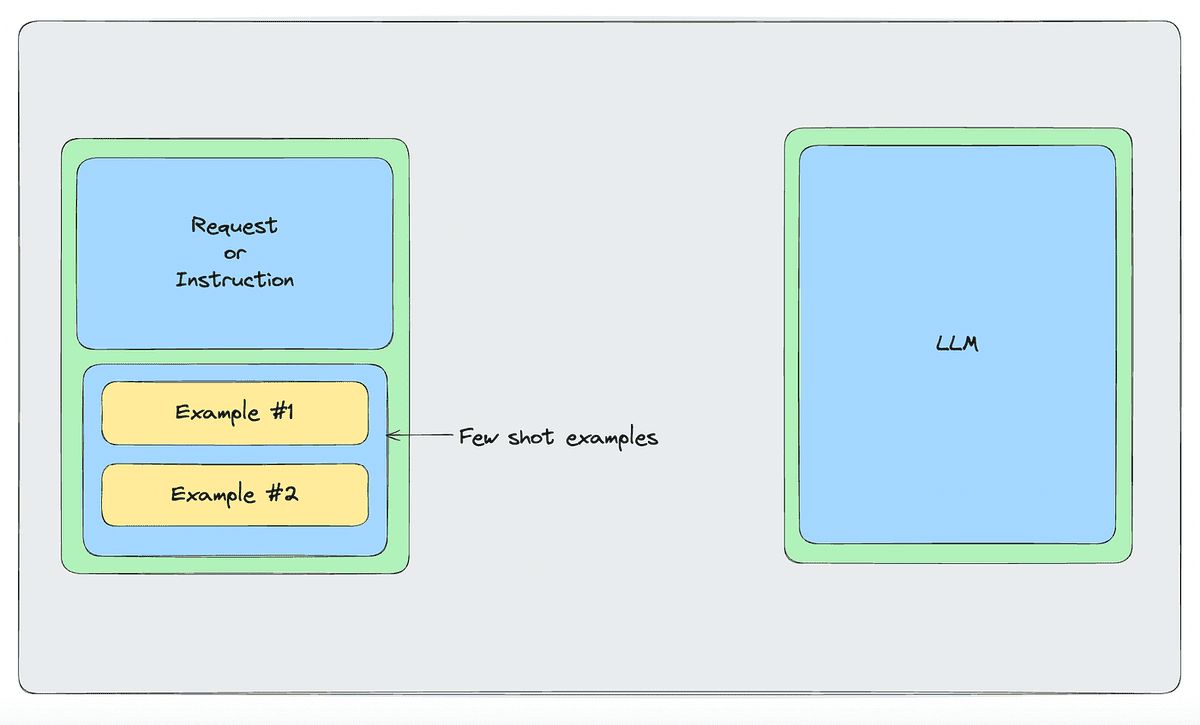
Few-shot prompting is a technique used with large language models (LLMs) whereby the model is provided with a limited number of input-output examples within the prompt to guide its response to a specific task. This approach leverages the model’s pre-trained knowledge, enabling it to perform tasks with minimal additional data.
Few shot prompting helps guide the model towards generating the kind of response we want. But that is mostly stylistic or formal (helping the model understand the kind of answers we expect (short/long) or the kind of reasoning steps we want it to mimic (reason, act, observe…).
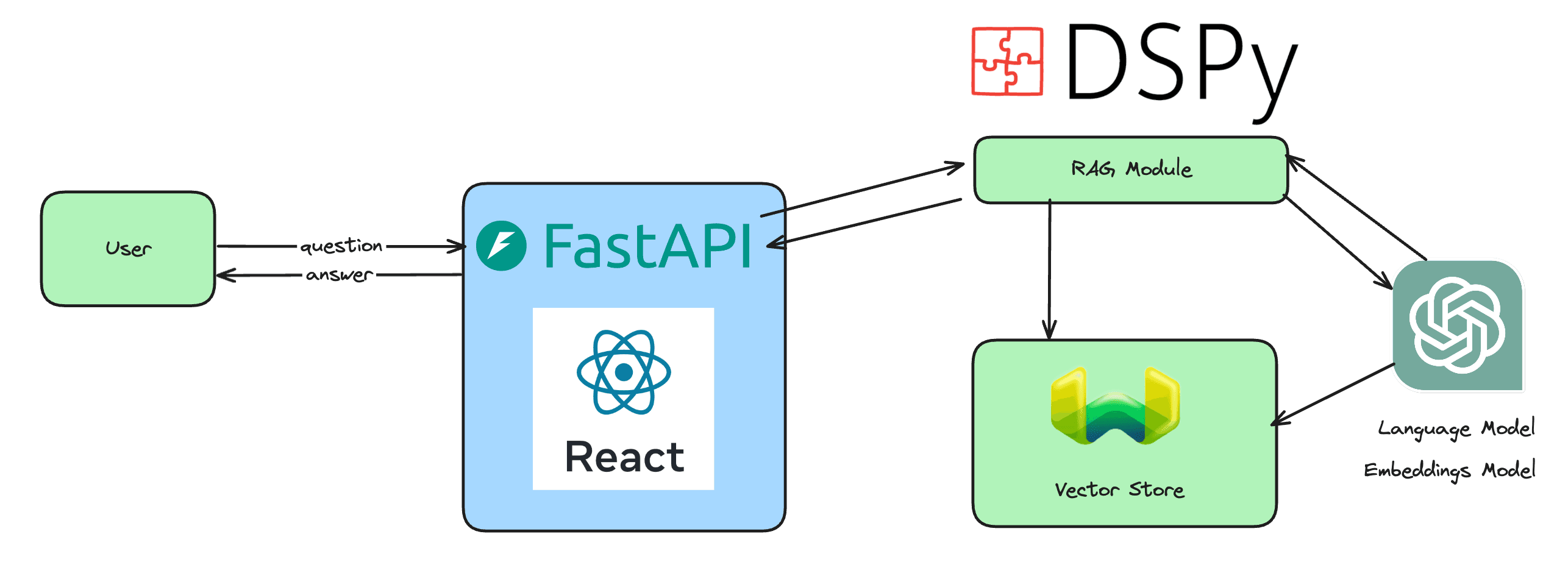
This is very different to RAG where what is added to the context is supposed to be the information needed to generate the correct answer.
Few shot prompting seems to be effective when the task is highly common or the model can easily understand the rule by induction. For example classifying sentences as positive or negative. The task is close to what we expect from LLMs given their ability to quickly get semantic cues. Thus, every task that requires mostly the ability to get semantic cues is a good candidate for few shot prompting.
Notably, few shot prompting fails when the task at hand requires multi-step reasoning or the induction the model can achieve based on examples is not strong enough.
Let’s say you do automatic few shot prompting on your question answering system. So every time you receive a question from a user, you pull out some question/answer pairs from your QA database and add them as examples. This will work great as a way to teach the LLM the style of answers you expect. What it won’t do is help the LLM in any way at the question at hand, except if by chance one of the QA pairs you randomly got contains the answer to the specific query you got from the user. The best way to improve a QA pipeline is thus probably to do some variation of RAG based on the QA dataset. So when you get a question from the user, you can provide few shot examples that likely contain the answer to the question and thus nudge the model into giving the correct answer.
This approach is perfectly coherent with a meme I saw on X recently saying a LLM giving the correct answer basically lies in the person prompting knowing the answer and thus subconsciously guiding the model towards it. I wish I could find the original image of that meme, because there is a lot of truth to it. It’s beneficial to remember that the more relevant information you provide an LLM, the greater the likelihood it will produce a correct answer.
Let’s run an experiment to determine which prompting strategy is effective for QA systems. For that purpose we are going to use BERT for semantic similarity and retrieve HotpotQA from Hugging Face’s datasets library. We’ll use BERT embeddings to identify semantically similar examples in the few-shot prompting scenario.
We will consider three scenarios:
- No-shot Prompting: We prompt the LLM by asking the question directly without adding any few-shot examples.
- Random Few-shot Prompting: We prompt the LLM with a few-shot example randomly selected from the HotpotQA dataset.
- Semantic Similarity Few-shot Prompting with BERT: We prompt the LLM with few-shot examples selected based on semantic similarity to maximize the chance of providing the correct answer in context, improving the LLM’s accuracy.
Each scenario will be run 10 times, and results will be stored in separate lists for later analysis.
We will use a different LLM (from the one used for answer generation) to evaluate whether the predicted answers match the correct answers.
Here is the code to run the experiments. The first file contains the logic necessary to run one experiment for all scenarios.
import os
import pandas as pd
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModel
import torch
from openai import OpenAI
from dotenv import load_dotenv
import logging
from tqdm import tqdm # Progress bar
# Load environment variables
load_dotenv()
# Set up logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# Initialize client
client = OpenAI(
base_url="https://api.studio.nebius.ai/v1/",
api_key=os.environ.get("NEBIUS_API_KEY"),
)
# Load tokenizer and model for BERT-based similarity (using 'bert-base-uncased' as an example)
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModel.from_pretrained("bert-base-uncased")
# Load HotpotQA dataset and select 30 random questions from the validation split
dataset = load_dataset("hotpot_qa", "fullwiki")
sampled_questions = dataset["validation"].shuffle(seed=45).select(range(30))
logging.info(f"Sampled questions selected from HotpotQA dataset. Number of questions: {len(sampled_questions)}")
hotpotqa_df = sampled_questions.to_pandas()
# Function to get BERT embeddings
def get_embedding(text):
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True)
outputs = model(**inputs)
return outputs.last_hidden_state.mean(dim=1)
# Function to retrieve top k similar examples based on cosine similarity
def get_top_k_similar_examples(question, dataset_df, k=3):
question_embedding = get_embedding(question)
similarities = []
for _, row in dataset_df.iterrows():
example_embedding = get_embedding(row["question"])
similarity = torch.cosine_similarity(question_embedding, example_embedding).item()
similarities.append((similarity, row))
# Sort by similarity and select top k examples
top_k_examples = sorted(similarities, key=lambda x: x[0], reverse=True)[:k]
return [example[1] for example in top_k_examples]
# Prepare results storage
no_shot_results = []
random_few_shot_results = []
semantic_few_shot_results = []
# Processing loop with progress bar
for i in range(1):
logging.info(f"Starting iteration {i+1}")
for idx, row in tqdm(hotpotqa_df.iterrows(), total=len(hotpotqa_df), desc="Processing Questions"):
question = row['question']
answer = row['answer']
# Log the question being processed
logging.info(f"Processing question: {question}")
# No-shot Prompting
logging.info(f"Scenario: No-shot Prompting")
messages = [{"role": "user", "content": question}]
response = client.chat.completions.create(
model="meta-llama/Meta-Llama-3.1-405B-Instruct",
messages=messages,
)
predicted_answer = response.choices[0].message.content
logging.info(f"No-shot predicted answer: {predicted_answer}")
no_shot_results.append({'question': question, 'predicted_answer': predicted_answer, 'real_answer': answer})
# Random Few-shot Prompting
logging.info(f"Scenario: Random Few-shot Prompting")
few_shot_examples = hotpotqa_df.sample(n=3) # Random selection
prompt_examples = "\n".join([f"Q: {ex['question']} A: {ex['answer']}" for _, ex in few_shot_examples.iterrows()])
prompt = f"{prompt_examples}\nQ: {question}"
messages = [{"role": "user", "content": prompt}]
response = client.chat.completions.create(
model="meta-llama/Meta-Llama-3.1-405B-Instruct",
messages=messages,
)
predicted_answer = response.choices[0].message.content
logging.info(f"Random Few-shot predicted answer: {predicted_answer}")
random_few_shot_results.append({'question': question, 'predicted_answer': predicted_answer, 'real_answer': answer})
# Semantic Similarity Few-shot Prompting
logging.info(f"Scenario: Semantic Similarity Few-shot Prompting")
few_shot_examples = get_top_k_similar_examples(question, hotpotqa_df, k=3)
prompt_examples = "\n".join([f"Q: {ex['question']} A: {ex['answer']}" for ex in few_shot_examples])
prompt = f"{prompt_examples}\nQ: {question}"
messages = [{"role": "user", "content": prompt}]
response = client.chat.completions.create(
model="meta-llama/Meta-Llama-3.1-405B-Instruct",
messages=messages,
)
predicted_answer = response.choices[0].message.content
logging.info(f"Semantic Few-shot predicted answer: {predicted_answer}")
semantic_few_shot_results.append({'question': question, 'predicted_answer': predicted_answer, 'real_answer': answer})
# Convert results to DataFrames and save as CSV
no_shot_df = pd.DataFrame(no_shot_results)
random_few_shot_df = pd.DataFrame(random_few_shot_results)
semantic_few_shot_df = pd.DataFrame(semantic_few_shot_results)
no_shot_df.to_csv('no_shot_results.csv', index=False)
random_few_shot_df.to_csv('random_few_shot_results.csv', index=False)
semantic_few_shot_df.to_csv('semantic_few_shot_results.csv', index=False)
# Log completion
logging.info("All scenarios processed and results saved to CSV files.")The second file contains the code to run evals for each scenario. We use a LLM as judge approach here.
import os
import pandas as pd
from openai import OpenAI
from dotenv import load_dotenv
import logging
from tqdm import tqdm # Progress bar
import csv
# Load environment variables
load_dotenv()
# Set up logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# Initialize client for evaluation LLM
client = OpenAI(
base_url="https://api.studio.nebius.ai/v1/",
api_key=os.environ.get("NEBIUS_API_KEY"),
)
# Load saved results from CSV files
no_shot_df = pd.read_csv('no_shot_results.csv')
random_few_shot_df = pd.read_csv('random_few_shot_results.csv')
semantic_few_shot_df = pd.read_csv('semantic_few_shot_results.csv')
# Open CSV file in write mode to write results one by one
with open('evaluation_results.csv', mode='w', newline='') as file:
writer = csv.writer(file)
# Write header
writer.writerow(['scenario', 'question', 'correct'])
# Evaluate each scenario's results
for df, scenario in [(no_shot_df, 'no-shot'), (random_few_shot_df, 'random few-shot'), (semantic_few_shot_df, 'semantic few-shot')]:
logging.info(f"Evaluating scenario: {scenario}")
for idx, row in tqdm(df.iterrows(), total=len(df), desc=f"Evaluating {scenario}"):
question = row['question']
predicted_answer = row['predicted_answer']
real_answer = row['real_answer']
messages = [
{
"role": "user",
"content": (
f"Is the predicted answer correct?\n"
f"Predicted: {predicted_answer}\n"
f"Real answer: {real_answer}\n"
f"Put response in <response> tags and answer with 'yes' or 'no'. "
"For example, <response>yes</response> or <response>no</response>."
)
}
]
try:
response = client.chat.completions.create(
model="mistralai/Mixtral-8x22B-Instruct-v0.1",
messages=messages,
)
response_content = response.choices[0].message.content
logging.info(f"Response for evaluation: {response_content}")
# Extract response between <response> tags
start_tag = "<response>"
end_tag = "</response>"
start_idx = response_content.find(start_tag) + len(start_tag)
end_idx = response_content.find(end_tag)
if start_idx != -1 and end_idx != -1:
correct = response_content[start_idx:end_idx].strip().lower()
if correct == 'yes':
is_correct = True
elif correct == 'no':
is_correct = False
else:
# Fallback if unclear response
is_correct = 'yes' in response_content.lower()
else:
# If tags are missing, check if there's "yes" or "no" in response
is_correct = 'yes' in response_content.lower()
# Log each evaluation outcome
logging.info(f"Question: {question} | Predicted: {predicted_answer} | Real: {real_answer} | Correct: {is_correct}")
# Write result to CSV file
writer.writerow([scenario, question, is_correct])
file.flush() # Ensure data is written to disk
except Exception as e:
logging.error(f"Error during evaluation for question: {question} - {e}")
writer.writerow([scenario, question, None])
file.flush() # Ensure error row is written
logging.info("Evaluation completed and results saved one by one to 'evaluation_results.csv'")After running several experiments, here are the key observations:
 Few shot prompting results
Few shot prompting results
No-Shot Scenario:
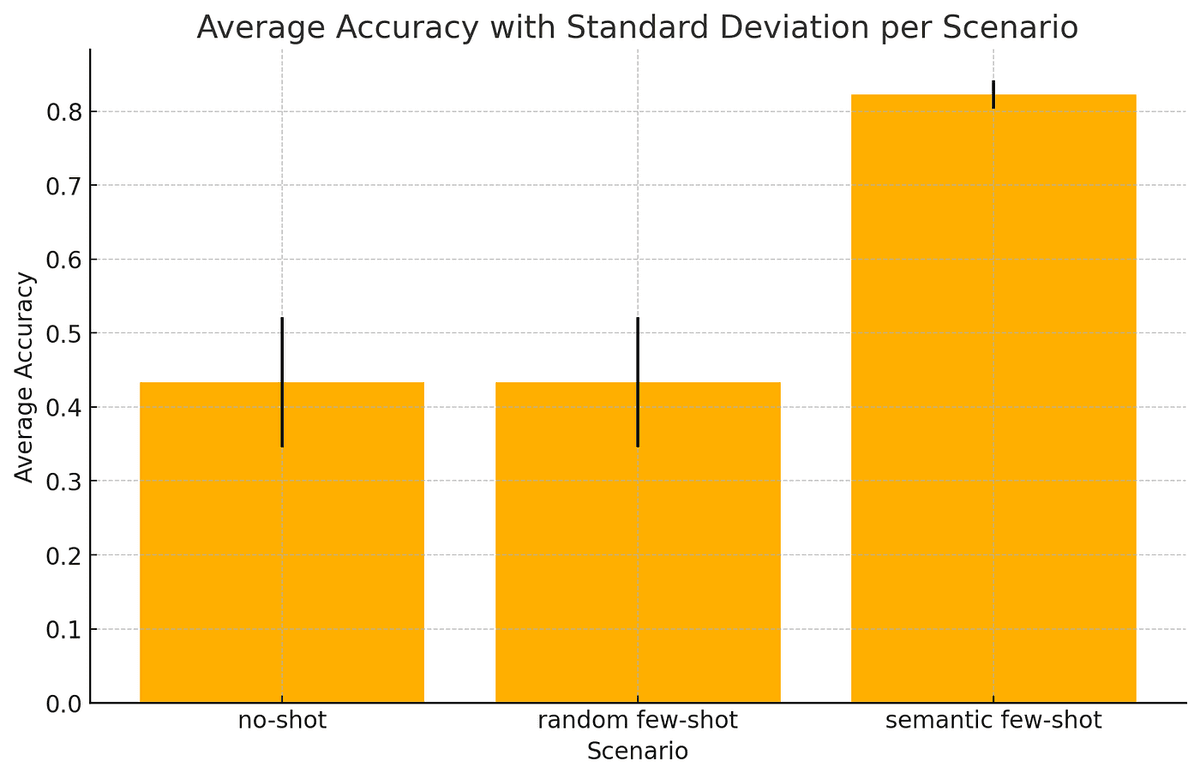
The no-shot approach yielded an average accuracy of approximately 44%, with results varying moderately across rounds (34% to 50%), indicating potential inconsistency across datasets.
Random Few-Shot Scenario:
The random few-shot setup performed with an average accuracy of around 43%. This is very similar to the no-shot scenario, indicating that merely adding random examples does not improve QA system accuracy.
The results varied moderately across rounds (from 37% to 53%), indicating potential inconsistency from one dataset to another.
Semantic Few-Shot Scenario
The semantic few-shot setup has consistently delivered the highest accuracy, averaging 83%. This approach demonstrated not only high accuracy but also relative stability across rounds (80% to 84%), suggesting that semantically similar examples effectively boost model performance.
Conclusion
Among all tested scenarios, the semantic few-shot setup shows clear superiority in terms of accuracy and reliability. This suggests that providing examples that are contextually relevant to the input is beneficial.