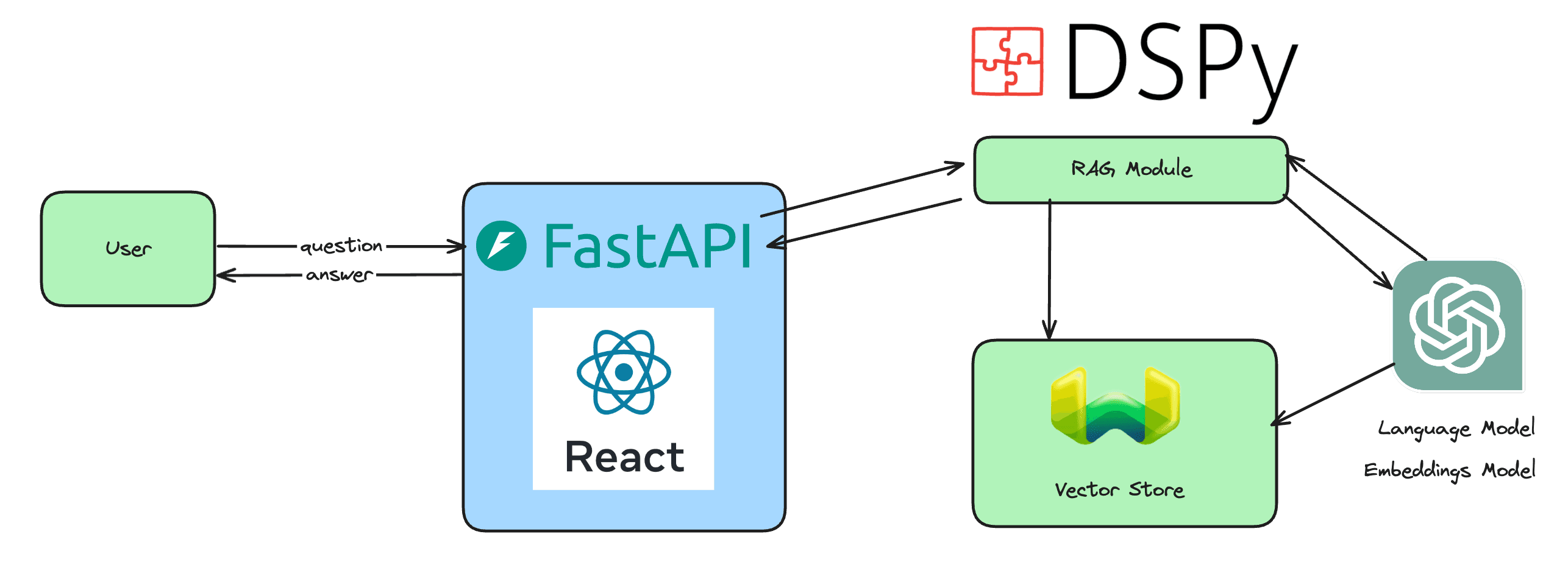
From simple LLM-based applications to compound AI systems
From simple LLM-based applications to compound AI systems
Nowadays, the majority of LLM-based applications go beyond the classic text completion/chat UI of ChatGPT’s early days. No more text in, text out. It is no longer enough. Why? Because most LLM-based applications are now compound AI systems. What that means is that the LLM is now one component that has to interact with other components (usually via their API).
To do so, the LLM has to be able to generate structured outputs that can be parsed into the parameters needed by other components it interacts with. The perfect analogy for this can be found in web development. Usually, the backend API interacts with the frontend by exchanging data in JSON. Similarly, LLMs have to be able to reliably generate JSON outputs or similar structured outputs to interact with other components.
From unstructured to structured
Two years ago, when GPT-3 was released and made available through an API, structured output generation was not that reliable. AI engineers had to rely on prompt shenanigans and expensive retry logics.
Nowadays, it is much easier to achieve this. Models are trained or finetuned in a way that makes them more reliable at structured output generation.
An early method for structured output generations was to ask the LLM to respond using some HTML tag, or XML. For some reason (probably due to data seeing during training), LLMs are good at answering using XML.
What is interesting with that approach is that XML is easy to parse with simple regexes. This approach has lost in popularity but can still be used in some cases.
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
client = OpenAI(
base_url="https://api.studio.nebius.ai/v1/",
api_key=os.environ.get("NEBIUS_API_KEY"),
)
SCHEMA = """
<employee>
<name>John Doe</name>
<title>Senior Software Engineer</title>
<department>Engineering</department>
<salary>$120,000</salary>
</employee>
"""
messages = [
{
"role": "user",
"content": "Alice Ford, Software Engineer, Engineering, $100,000"
},
{
"role": "user",
"content": f"Parse the employeed details into this schema: {SCHEMA}",
}
]
response = client.chat.completions.create(
model="meta-llama/Meta-Llama-3.1-405B-Instruct",
messages=messages,
)
def get_tag_content(tag: str, xml: str) -> str:
start_tag = f"<{tag}>"
end_tag = f"</{tag}>"
start_index = xml.find(start_tag)
end_index = xml.find(end_tag)
return xml[start_index + len(start_tag):end_index]
def xml_to_dict(xml: str) -> dict:
name = get_tag_content("name", xml)
title = get_tag_content("title", xml)
department = get_tag_content("department", xml)
salary = get_tag_content("salary", xml)
return {
"name": name,
"title": title,
"department": department,
"salary": salary
}
content = response.choices[0].message.content
print(xml_to_dict(content))A more robust and common approach, especially for OpenAPI compatible servers, is guided JSON.
With guided JSON, you can define the structure of The outputs you need using a pydantic BaseModel class. Here is an example:
from pydantic import BaseModel, Field
from openai import OpenAI
from dotenv import load_dotenv
import os
import json
load_dotenv()
client = OpenAI(
base_url="https://api.studio.nebius.ai/v1/",
api_key=os.environ.get("NEBIUS_API_KEY"),
)
class EmployeeInfo(BaseModel):
name: str = Field(...,
description="The name of the employee.")
title: str = Field(...,
description="The title of the employee",
examples=["Data scientist", "Software engineer"])
department: str = Field(...,
description="The department the employee works in")
salary: float = Field(...,
description="The salary of the employee.",
pattern='^\$\d+$')
messages = [{"role": "user",
"content": """John Doe is the new Senior Software Engineer in the
Engineering department with a salary of $120,000."""}]
completion = client.chat.completions.create(
model="meta-llama/Meta-Llama-3.1-405B-Instruct",
messages=messages,
extra_body={
'guided_json': EmployeeInfo.model_json_schema()
}
)
generated_json = json.loads(completion.choices[0].message.content)
print(json.dumps(generated_json, indent=2))The result will be a JSON that you can then parse and print like this:
{
"name": "John Doe",
"title": "Senior Software Engineer",
"department": "Engineering",
"salary": 120000
}Grounding
Let’s see in practice how structured output generation can be useful when building a compound AI system.
One way to reduce hallucinations and increase the usefulness of your AI system is to give it access to the internet. This way, the LLM response can be generated based on reliable up-to-date sources. Here is how to do so using the SERPAPI.
Overall, the user asks a question, the AI system analyzes it and decides if there is a need to gather more information via the internet. If so, then it passes the parameters of the required request to the SERPAPI.
Finally, the results from SERPAPI are processed and used to ground the final response generated by the LLM.
from pydantic import BaseModel, Field, model_validator
from openai import OpenAI
from dotenv import load_dotenv
import os
import json
from datetime import datetime
from serpapi.google_search import GoogleSearch
load_dotenv()
client = OpenAI(
base_url="https://api.studio.nebius.ai/v1/",
api_key=os.environ.get("NEBIUS_API_KEY"),
)
class SearchRequest(BaseModel):
"Parameters for search request using SerpApi"
query: str = Field(..., title="Search query")
location: str = Field(..., title="Location to search from")
date: str = Field(
default_factory=lambda: datetime.now().strftime("%Y-%m-%d"),
title="Date to search from"
)
@model_validator(mode="before")
def check_date_provided(cls, values):
if "date" not in values or values["date"] is None:
raise ValueError("The 'date' field is required.")
return values
messages = [
{
"role": "user",
"content": """Who is set to be the Director of National Intelligence
in Donald Trump's second administration ?"""
}
]
completion = client.chat.completions.create(
model="meta-llama/Meta-Llama-3.1-405B-Instruct",
messages=messages,
extra_body={
'guided_json': SearchRequest.model_json_schema()
}
)
generated_json = json.loads(completion.choices[0].message.content)
print(generated_json)
params = {
"q": generated_json["query"],
"location": generated_json["location"],
"hl": "en",
"google_domain": "google.com",
"api_key": os.environ.get("SERPAPI_API_KEY")
}
search = GoogleSearch(params)
results = search.get_dict()
messages.append(
{
"role": "assistant",
"content": f"I should use these results from Google: {results}"
}
)
final_response = client.chat.completions.create(
model="meta-llama/Meta-Llama-3.1-405B-Instruct",
messages=messages,
)
print(final_response.choices[0].message.content)This is just one example, but a similar feat can be achieved with other APIs.
To conclude, as LLMs become integral components of compound AI systems, the need for reliable, structured outputs has become more pressing. Moving beyond simple text completion, modern applications require LLMs to produce outputs that other systems can easily parse and use, often through structured formats like JSON or XML. Techniques like guided JSON for OpenAI compatible servers help ensure that LLM responses are both predictable and usable within broader system architectures.