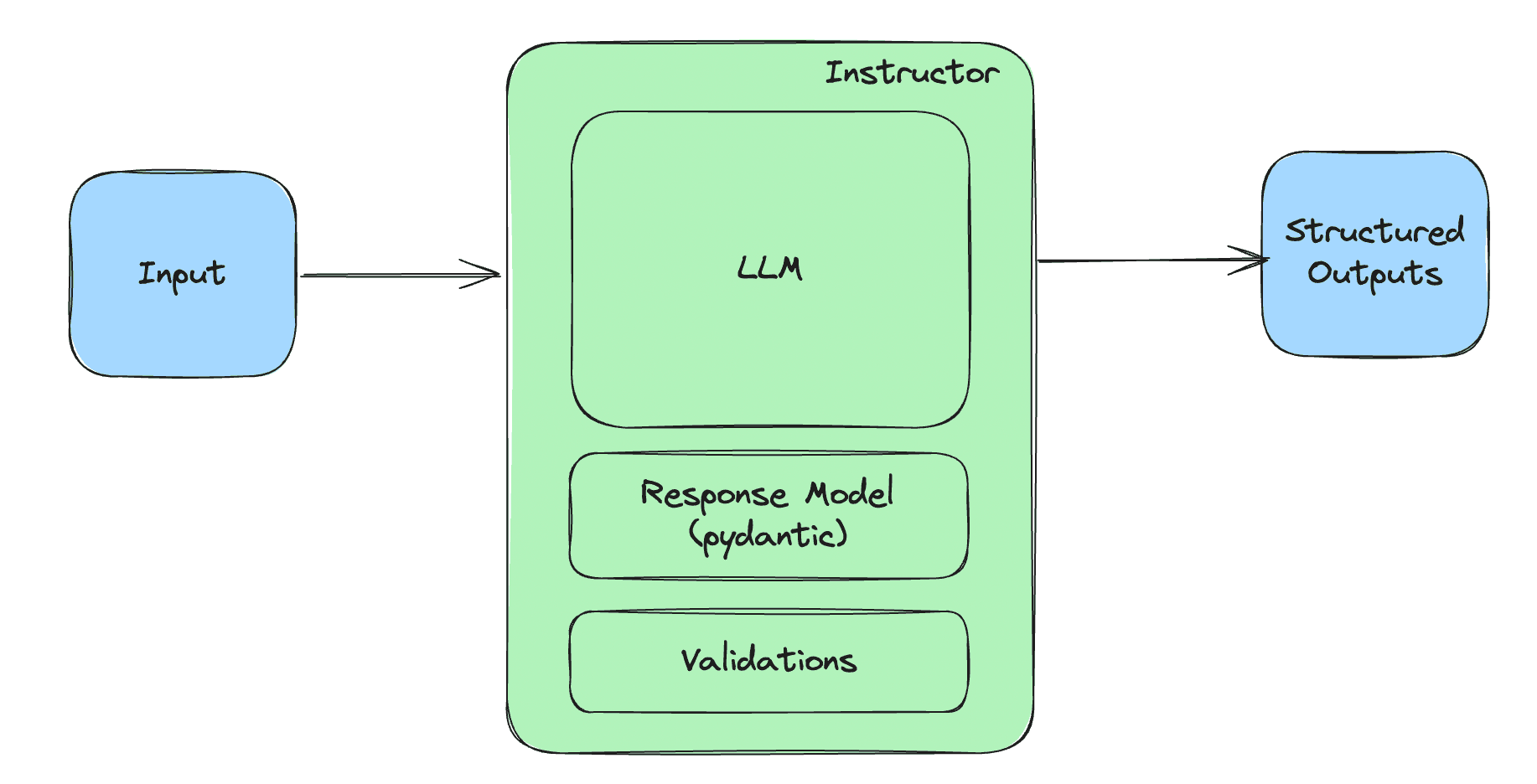
OpenAI has just released its latest LLM, named o1, which has been trained through reinforcement learning to "think" before answering questions. Here, "think" refers to the chain of thought technique, which has proven effective in improving the factual accuracy of LLMs. This is an example of a prompting technique that is usually applied externally but has now been "internalized" during the model's training. This is not the first instance of such internalization. Recently, OpenAI released a new version of GPT-4, trained to generate structured data (JSON, etc.), something that was previously possible mainly through Python packages like Instructor, which combined prompting methods with API call repetition and feedback to push the model to produce the desired type of structured data.
I theorize that we will continue to see this trend of internalizing features, from the prompting layer to the model layer. What's next? Perhaps internalizing techniques like the tree of thoughts so that before providing an answer, the LLM is capable of generating multiple possible responses in the search space and choosing the best one from there.
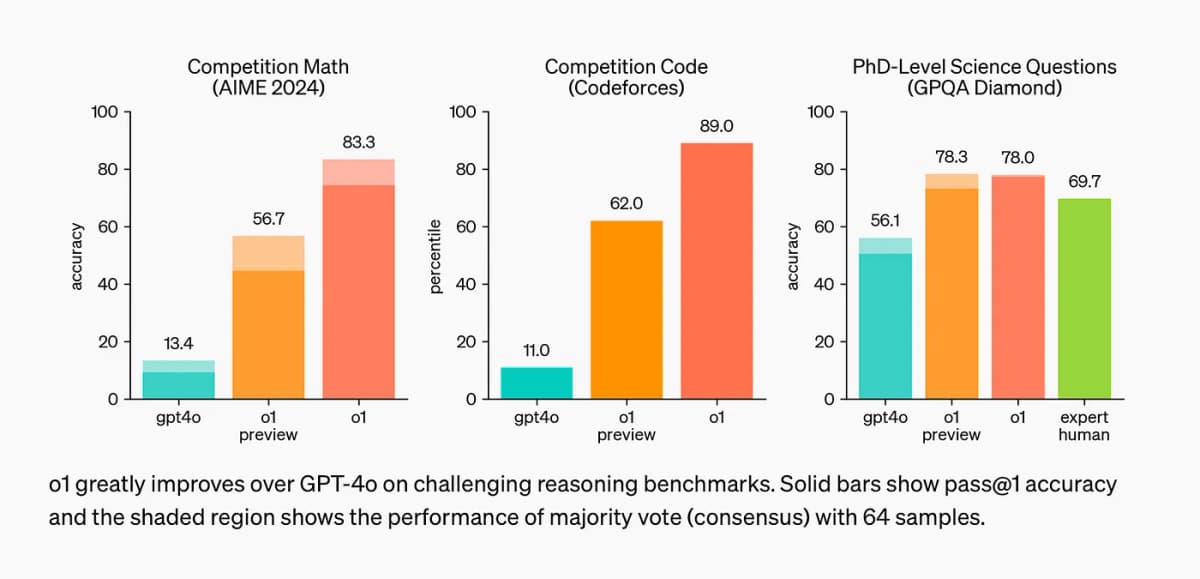
Anyway, let's focus on o1 for now. The announcement was well received on Twitter. It's worth noting that OpenAI and its CEO, Sam Altman, had built up a lot of hype in the weeks and months leading up to this release. o1 clearly demonstrates impressive performance on benchmarks that require "reasoning" - 89th percentile on competitive programming questions (Codeforces), ranking among the top 500 students in the US in a qualifier for the USA Math Olympiad (AIME), and exceeding human PhD-level accuracy on a benchmark of physics, biology, and chemistry problems (GPQA). The performance is evidently superior to GPT-4, based on the results shared by OpenAI.
It's important to know that these announcements come at a time when OpenAI is aiming to raise $6.5 billion from investors at a valuation of $150 billion. So, releasing a product that shows they're still ahead of the competition clearly helps make the case that betting on their success is the right move.

An important point is that o1's accuracy increases with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute). However, it is not certain if this will continue to scale.
Despite the impressive capabilities of o1, there are significant concerns regarding the cost and control associated with its internal CoT system. Developers using o1 have no control over how the internal CoT process unfolds or how much it costs. Since reasoning tokens are billed as output tokens, users might find themselves paying for long, complex CoT reasoning steps, yet they have no insight into or ability to inspect the raw CoT process. This lack of transparency can make it difficult to manage costs effectively, especially for those with budget constraints.
For users who wish to retain control over the reasoning process and costs, a more traditional approach is still available. Instead of relying on internal CoT models like o1, developers can use common LLMs and implement their own CoT prompting externally. Libraries like DSPy are excellent tools for achieving this. DSPy allows developers to guide the reasoning process manually, giving them complete visibility into the steps the model takes and enabling better cost control. By managing the CoT prompts themselves, developers can optimize the number of tokens used and ensure they aren't paying for unnecessary complexity.
For those interested in learning how to use DSPy effectively, Lycee AI offers excellent courses that dive deep into how to implement CoT reasoning manually. These courses teach the fundamentals of controlling the reasoning flow of LLMs, helping developers not only improve accuracy but also manage the financial aspects of LLM-based systems more efficiently.

My point of view: this is a real advancement. I've always believed that with the right data allowing the LLM to be trained to imitate reasoning, it's possible to improve its performance. However, this is still pattern matching, and I suspect that this approach may not be very effective for creating true generalization. As a result, once o1 becomes generally available, we will likely notice the persistent hallucinations and faulty reasoning, especially when the problem is sufficiently new or complex, beyond the "reasoning programs" or "reasoning patterns" the model learned during the reinforcement learning phase.
The advantage of this approach is that it confirms an intuition I've had for a few months now: a large portion of knowledge work that requires "reasoning" can be automated through this new form of automation, which I've called "data-intensive automation." This is the same principle behind efforts by companies like Tesla and Waymo for self-driving cars. By applying reinforcement learning with a vast amount of reasoning or problem-solving examples, you can create a system at least as good as any human knowledge worker, which could significantly boost their productivity.
However, as we move forward, balancing performance gains with cost control and transparency will be essential for making LLM-based systems truly practical at scale.