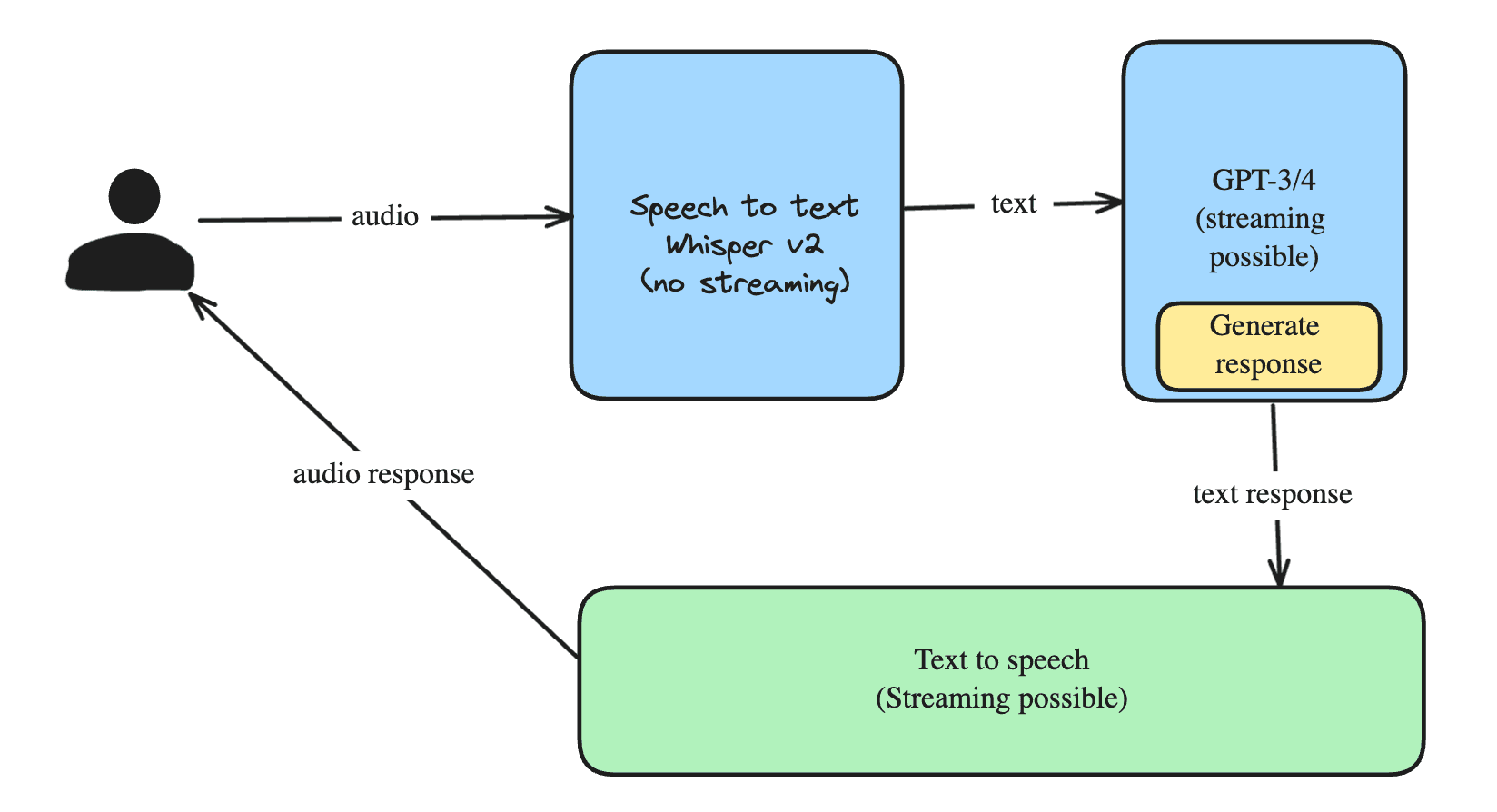
The concept of hallucination in LLMs refers to the generation of content that, while plausible, is not grounded in factual data. This issue stems from the underlying architecture of LLMs, which are designed to predict the next word in a sequence based on probabilities derived from their training data. Unlike humans, who base their responses on real-world knowledge, these models rely on word associations rather than factual accuracy. As a result, when LLMs encounter obscure or controversial topics that are not well-represented in their training data, they may produce incorrect or misleading information.
A recent study by researchers Jim Waldo and Soline Boussard highlights the risks associated with this limitation. In their analysis, they tested several prominent models, including ChatGPT-3.5, ChatGPT-4, Llama, and Google’s Gemini. The researchers found that while the models performed well on well-known topics with a large body of available data, they often struggled with subjects that had limited or contentious information, resulting in inconsistencies and errors.
This challenge is particularly concerning in fields where accuracy is critical, such as scientific research, politics, or legal matters. For instance, the study noted that LLMs could produce inaccurate citations, misattribute quotes, or provide factually wrong information that might appear convincing but lacks a solid foundation. Such errors can lead to real-world consequences, as seen in cases where professionals have relied on LLM-generated content for tasks like legal research or coding, only to discover later that the information was incorrect.
The issue of hallucination raises broader questions about "epistemic trust"—the philosophical concept of how we determine whether information is trustworthy. LLMs operate similarly to crowdsourced platforms like Wikipedia, drawing from vast datasets that reflect the most common online discussions. While this approach works well for general knowledge and widely agreed-upon topics, it becomes problematic for less-documented or more divisive issues, where consensus may be lacking.
In light of these challenges, experts are urging caution in the use of LLMs for critical or sensitive tasks. While these models excel in generating coherent and contextually appropriate text for general queries, they can falter in specialized fields where accuracy is paramount. The study underscores the importance of understanding the limitations of these systems, particularly as they are increasingly integrated into professional and academic environments.
The ongoing debate around the term "hallucination" itself reflects the complexity of the issue. Critics argue that the term anthropomorphizes LLMs, giving the false impression that these models possess human-like cognition or intent. Some suggest using alternative terms such as "confabulation" or "bad output" to describe the phenomenon more accurately. However, others maintain that "hallucination" effectively conveys the concept of generating incorrect but convincing information, despite the risk of oversimplifying the technology’s nature.
Several users of LLMs have shared personal experiences with the models’ limitations. For instance, in coding environments, LLMs may occasionally generate plausible but incorrect code, such as mixing up syntax or referencing deprecated functions. Similarly, when answering factual queries, models may rely too heavily on previous prompts, leading to context-dependent errors.
While some experts argue that LLMs go beyond mere autocomplete systems, suggesting they possess an internal "world model" built from their training data, others emphasize that these systems still lack true understanding. The accuracy of their responses depends heavily on the quantity and quality of the data they are trained on, which can vary significantly depending on the subject matter.
As AI technology continues to advance, it remains crucial to recognize the limitations of LLMs and ensure that they are used appropriately. Researchers and industry leaders are advocating for increased transparency, user education, and the development of more robust guardrails to mitigate the risks associated with hallucinations. Until then, the use of these powerful tools should be approached with caution, particularly in contexts where accuracy and reliability are essential. We can reduce the risk of hallucinations but may never fully eliminate them, given the inherent nature of LLMs and their reliance on statistical patterns rather than true understanding.