There has been a barrage of negative news about generative AI lately. OpenAI has moderated its expectations, scaling down the fanfare around its future product launches. In another instance, Google faced backlash for its "Dear Sydney" Gemini ad during the Olympics, raising questions about the appropriate role of AI in content creation. Moreover, concerns about the sustainability of the generative AI market have been voiced, with some speculating that it might be a bubble.
There certainly is a hype about generative AI, and I have been cautiously arguing against it recently because it masks the true value generative AI can bring by hyping impossible things that will eventually backfire. While generative AI holds significant potential to transform industries and improve human productivity, the excessive enthusiasm often projected can lead to unrealistic expectations. This overhype not only distracts from the practical and immediately beneficial applications of the technology but also sets the stage for inevitable disappointments when ambitious projections fail to materialize.
Here is the thing about large language models (LLMs), for example: The cost of acquiring knowledge is decreasing, particularly for those who know how to think critically and ask questions. However, this does not directly translate into productivity gains or increased profits. You still need to determine how to effectively leverage that knowledge to achieve productivity gains or generate profits.
The process of transforming knowledge into productivity gains or tangible, profitable outputs is often called "knowledge application" or "knowledge utilization." This involves using acquired information and insights in practical, effective ways to enhance efficiency, innovation, and profitability in various settings, such as business, technology, and research. Another term closely related to this concept is "knowledge translation," which specifically refers to the implementation of knowledge in practical settings, particularly in fields like health care and policy making.
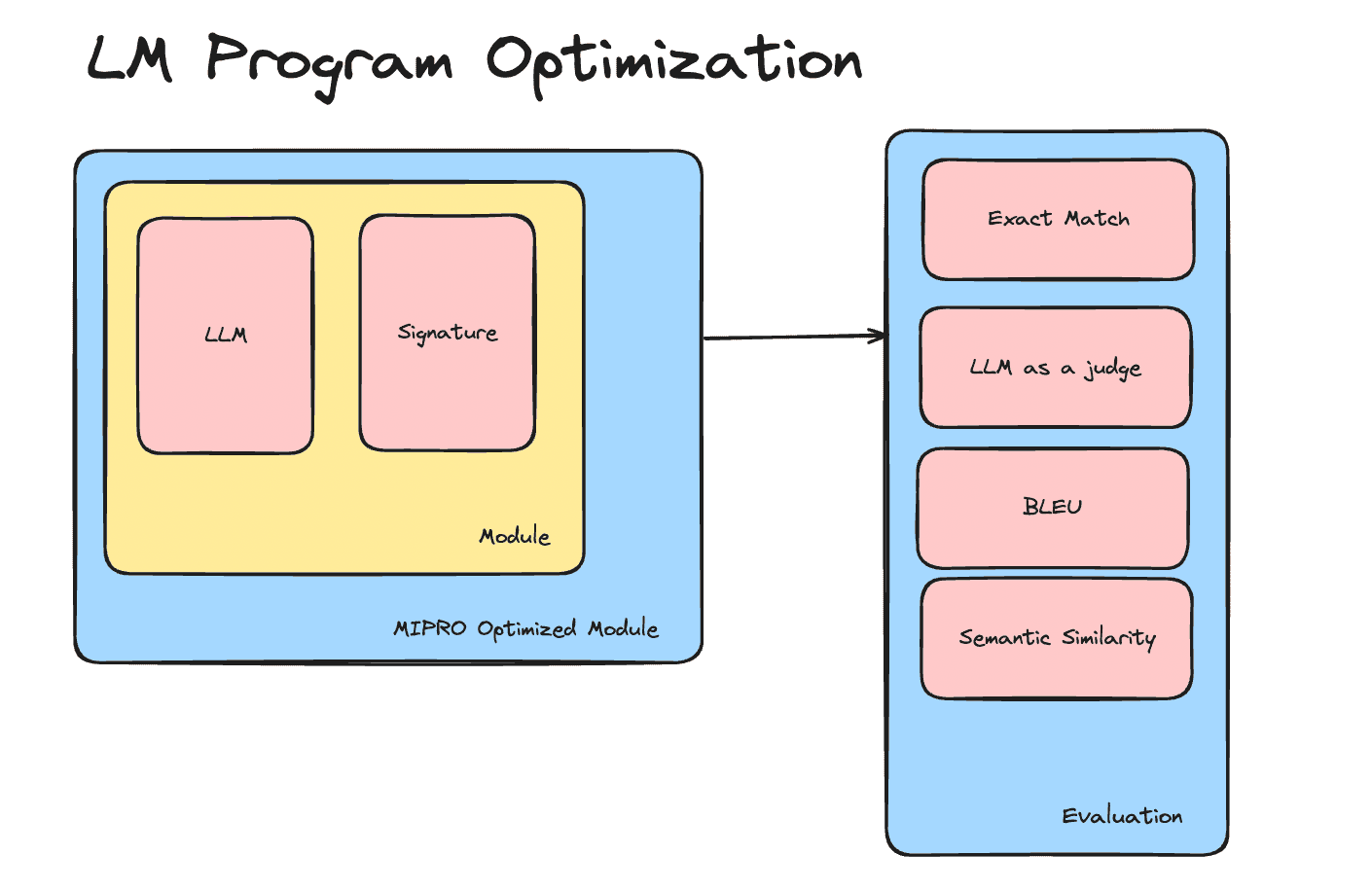
My firm belief is that the key to unlocking the value of LLMs, or more broadly, generative AI, lies in the application of knowledge. This is especially true for LLMs because they essentially compress knowledge available on the internet. It is less true for image and video generation, where the output is an asset that can be directly used. The primary concern for image/video/sound generation is asset quality and adherence to the desired style. For text generation, the primary concern is the relevance, coherence, and truthfulness of the generated text.
Process Automation
LLMs are not that good for automation because they have a reliability issue, as I discussed on this very blog recently: AI Reliability Challenge. However, they excel at transforming unstructured data into structured data at scale, even if imperfectly. They are particularly effective for classic NLP tasks like sentiment analysis, named entity recognition, classification, and cost-effective multilingual translation, although specialized models may perform better for specific use cases. LLMs simplify these tasks, enabling them to be executed at scale with just a single API call.
However, using LLMs for process automation is challenging due to the risk of generating incorrect or nonsensical outputs—what is often referred to as "hallucinations." Hallucinations happen mostly when the model has to process inputs that are out-of-distribution. When a model processes out-of-distribution inputs, it lacks the necessary data or context to generate accurate predictions or responses. This is often due to the limitations in the training data or the training process itself, which might not have encompassed a sufficiently wide range of examples or failed to capture complex dependencies within the data.
Systems that can operate effectively despite occasionally producing erroneous outputs are known as "fault-tolerant." But the problem with LLMs is that you don't even know when the output is incorrect or nonsensical. Consequently, you cannot build a fault-tolerant system on top of them. This is a significant limitation that restricts the application of LLMs in automation.
Since the output of Large Language Models (LLMs) is knowledge, it is essential to incorporate knowledge verifiers at each step to prevent catastrophic chain errors. This is feasible in some contexts, such as using LLMs to play chess. In this scenario, it's possible to systematically verify whether a move generated by the LLM is valid, as the set of permissible moves in any given chess position is well-defined and finite.
However, this approach is not universally applicable, especially in most business applications where the verification of knowledge output by LLMs isn't as straightforward. In many business contexts, the data is unstructured, the rules for correctness are not as clearly defined as in a game of chess, and the consequences of erroneous information can be more significant. Unlike chess, where each move has a clear set of possible responses, business decisions often depend on a variety of factors, including market conditions, human behavior, and economic variables, which are much harder to model and predict with precision.
Furthermore, even when verification mechanisms are in place, they do not necessarily guarantee the effectiveness of the system. For example, I developed an AI chess player using an LLM approach, which was systematically verified for the validity of each move. Despite this, the AI consistently lost matches against the Stockfish engine, a highly optimized chess program known for its superior performance. This highlights a critical point: ensuring that moves or decisions are valid within a given set of rules does not inherently mean they are strategically sound or effective.
This experience underscores the limitations of LLMs in contexts where decision-making requires not just rule-based validation but also strategic insight and adaptation to complex, dynamic environments. In business and other real-world applications, the challenge lies not only in generating and validating outputs but also in ensuring these outputs are contextually appropriate and strategically advantageous.
From knowledge to productivity and profits
Transforming knowledge into productivity and profit is more art than science. It involves strategic thinking, leveraging one’s strengths, and making the most of one's distribution channels. The development and implementation of tools, especially those powered by LLMs or other generative AI models, require a nuanced understanding of their capabilities as well as their limitations.
Creating tools that effectively use generative AI involves understanding the unique attributes of these technologies—such as their ability to analyze and synthesize large amounts of data rapidly and generate coherent outputs from complex inputs. However, designers must also account for their limitations, such as biases in the data they have been trained on, their potential for generating inaccurate or nonsensical outputs (hallucinations), and their general lack of understanding of human contexts.
The "billion dollar question" in leveraging generative AI models is about identifying and creating new kinds of tools that can revolutionize industries and business practices. This requires a deep understanding of the technology, the market, and the end-users. It also involves a willingness to experiment, iterate, and learn from failures. The potential for generative AI to transform industries is vast, but realizing this potential requires a thoughtful, strategic approach that balances innovation with practicality.