Photo by Igor Omilaev on Unsplash
I took time to read Langchain’s state of AI agents report, so you don’t have to. Don’t worry, you are not missing anything. It’s mostly a marketing pamphlet masqueraded as a rigorous study.
I knew it was bullshit from the get-go as soon as I read their definition of AI agents.
Here is the definition: “At Langchain, we define an agent as a system that uses an LLM to decide the control flow of an application.” Really?
Saying that an “agent” is defined as a system that uses an LLM to “decide the control flow” is at best an oversimplification and at worst, a misrepresentation.
In LLM-based applications, the LLM might generate responses that influence what happens next in a sequence, but it doesn’t actually “control” the program in any real autonomous sense. It is like saying Netflix is an AI agent because in the backend there is a recommendation system that “decides” what each user sees in the frontend. Adding a stochastic component to your application does not make it agentic!
At the end of the day, even for current LLM-based applications, the control flow is still generally predefined, with the LLM serving as a module that fits within that structure.
Photo by Mika Baumeister on Unsplash
True “agentic” systems would have a higher level of autonomy where they perceive, decide, and act independently of hardcoded instructions.
If you use Langchain’s definition, any standardized LLM-enhanced tool or chatbot would be considered an AI agent.
Hell, RAG is an AI agent based on that definition.
In short, Langchain’s definition is broad to the point of being nearly meaningless because it can apply to almost any application with an LLM integrated into it, regardless of whether it has genuine autonomy or agentic properties.
This dilution of definitions is now commonplace in the AI space. OpenAI has been practicing that when it comes to defining AGI. It always goes on like this:
-
Hype anything you do to its maximum (“AGI is near!”, “AI agents are working”…)
-
When reality starts to hit, broaden or dilute the definition of concepts so it fits what you said during the hype so you don’t look like a complete fool.
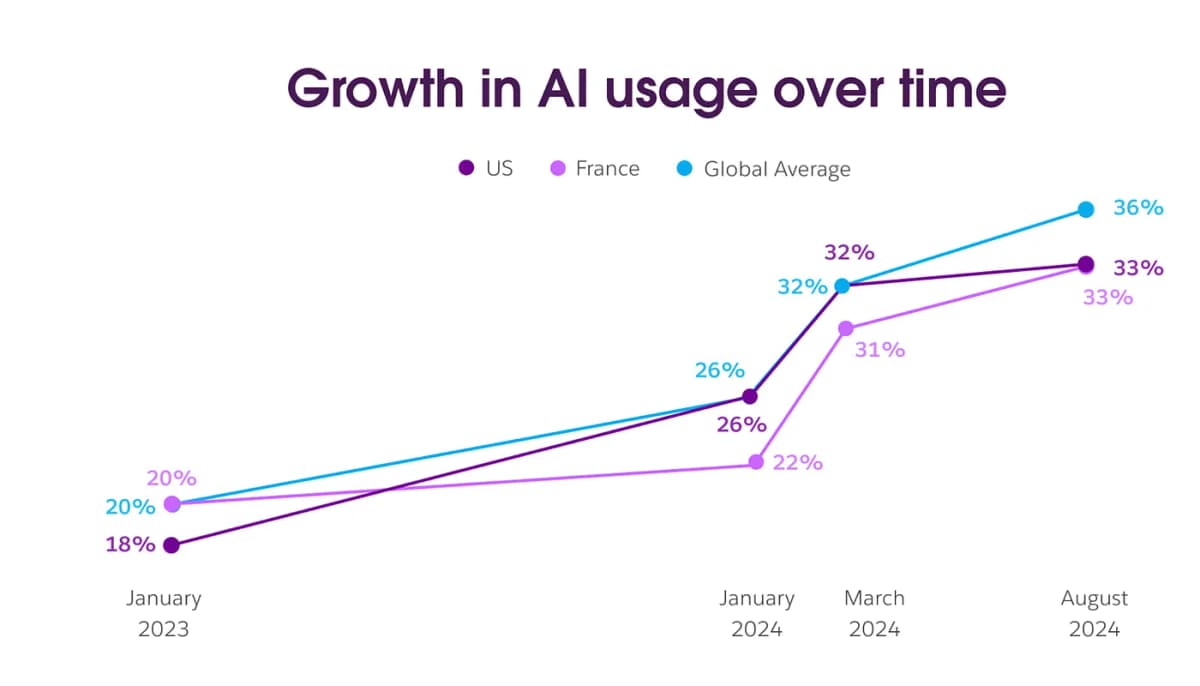 Growth in AI usage according to a recent Slack report
Growth in AI usage according to a recent Slack report
They even went as far as to call Cursor, Replit, and perplexity AI “AI agents.” Really? Cursor primarily functions as a tool providing assistance rather than acting autonomously.
Similarly, although Replit automates certain aspects of development, it operates based on user inputs and predefined settings, lacking autonomous decision-making capabilities. Perplexity AI? It is an advanced search tool that delivers information based on user queries without autonomous goal-setting or action.
If we start to consider these applications “AI agents,” then even ChatGPT is an AI agent. That’s a slippery slope I am not willing to embrace.
LLMs generate text based on patterns learned from their massive training datasets. They don’t “reason” in the way humans do; instead, they predict likely word (token) sequences based on statistical associations. True reasoning involves understanding context, making inferences, and sometimes even having intentions — all of which LLMs lack.
You will notice that I didn’t even question the wisdom of letting an LLM “decide” anything without proper verification and human in the loop. Now let me do just that.
LLMs are not reasoning engines. Repeat after me: “LLMs are not reasoning engines.” I don’t care what OpenAI or Sam Altman or Dario Amodei are saying. It’s all marketing. That’s a polite way to say it’s all lying or exaggerating or faking until making.
In their report, LangChain’s team write: “Unlike traditional LLMs, AI agents can trace back their decisions, including time traveling…” What? Time traveling? Are you serious?
I am sorry to break it to you, LangChain, LLMs can’t “time-travel” through their decisions or learn from past mistakes without being retrained. Saying LLMs exhibit “human-like reasoning” is just plain misleading.
LLMs are mostly knowledge bases that perform interpolative retrieval based on semantic cues. What that means is that a LLM can solve a problem not seen during training or fine-tuning just by retrieving the most similar “program” it has.
Sometimes it will be enough and work, but on a lot of occasions, because the problem is too out of distribution or because its formulation triggers the retrieval of a program (succession of words, sentences, approaches to solve the problem) that is not adapted. We saw that in how LLMs struggled with variations of the Monty Hall problem, generating fake reasoning traces just to give the most common answer found on the internet, even if fake for the particular variation. And there are many more examples like that.
So, using an LLM to “decide” anything supposes the LLM can reason reliably. It can’t. Human in the loop is the best way to counter that and keep LLMs useful as knowledge retrievers.