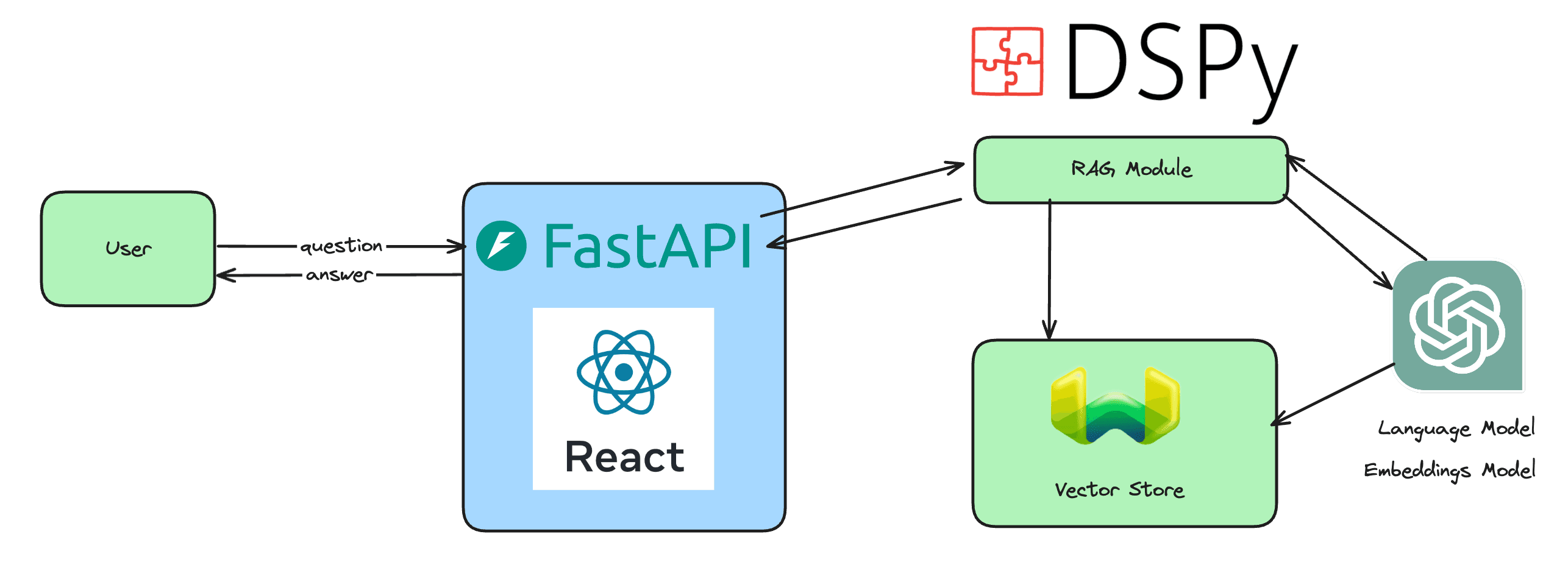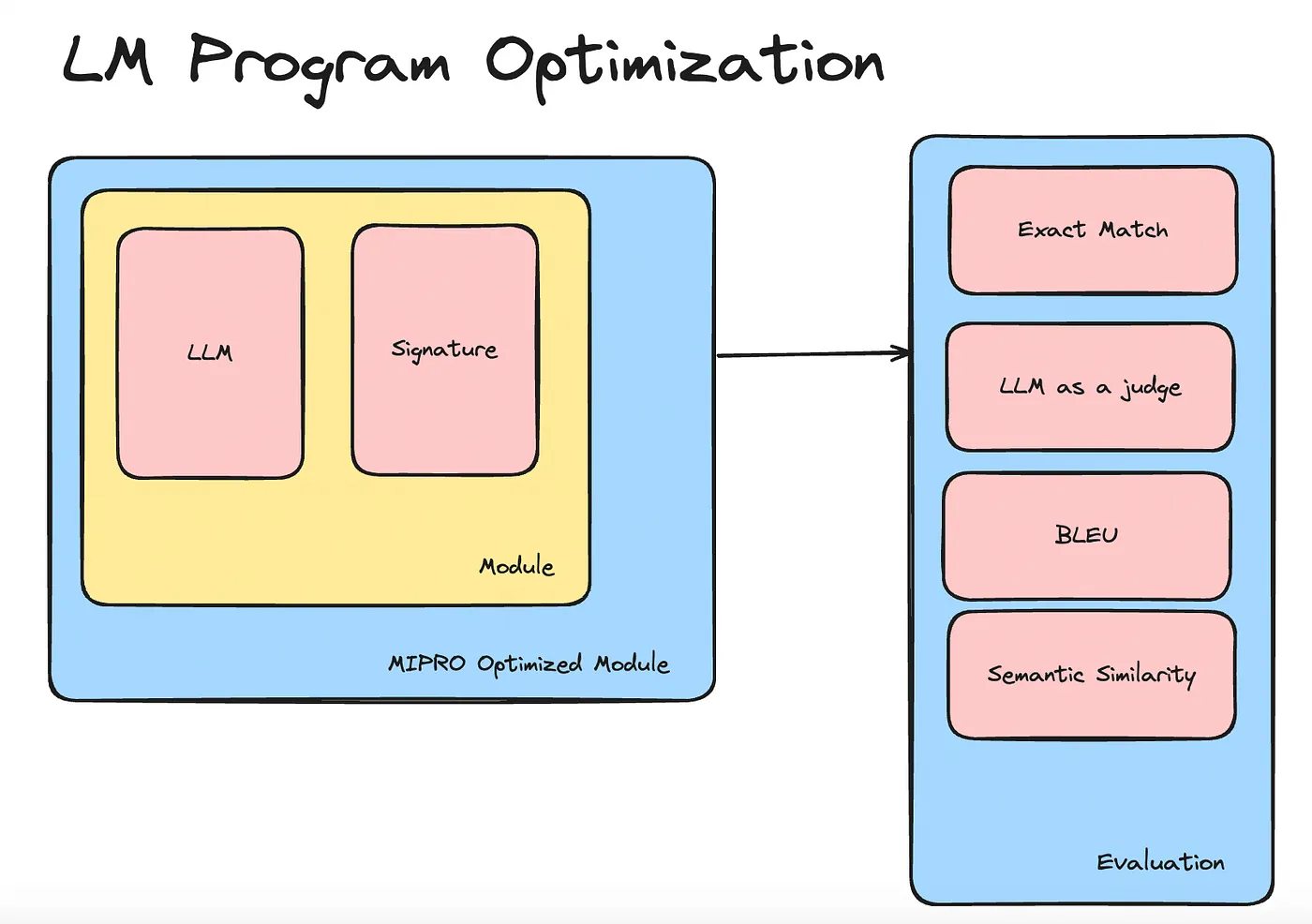
In the first article of this series, I showed how to build a Question-Answering (QA) system using DSPy and automatically optimize it with the MIPRO optimizer. I concluded that MIPRO-optimized QA systems outperform vanilla QA systems built with DSPy.
After writing that article, I decided to make my QA system more reliable by modifying the validate_answer metric. Previously, the system used Typed Predictors from DSPy. However, to enforce types and ensure the LLM responses match a structured format, I found the Instructor library more robust. I switched to using Instructor and updated the validate_answer function as follows:
# Define your desired output structure
class AnswerEval(BaseModel):
correct: bool = Field(..., description="whether the predicted answer is correct True/False")
# Patch the OpenAI client
client = instructor.from_openai(OpenAI())
# Function to check if the answer is correct
def validate_answer(example, pred, trace=None):
# use the LM to check if the answer is correct
# Extract structured data from natural language
answer_eval = client.chat.completions.create(
model="gpt-3.5-turbo",
response_model=AnswerEval,
messages=[{"role": "user", "content": f"Is the predicted answer '{pred.answer}' matching the reference answer '{example.answer}'?"}],
)
return answer_eval.correctBy using Instructor, I can ensure the LLM generates an output that matches a Pydantic model. In this case, I first define the AnswerEval model, which has a single field, correct. This field is a boolean that returns true if the predicted answer matches the reference answer. I then patch the OpenAI client with Instructor. After this, I can use the patched client just like the original OpenAI client. The only difference is that I pass a response_model (the Pydantic model I defined), and Instructor handles the rest. This way, I can be sure the answer_eval response will include a correct field.
I also decided to experiment with other validation metrics like spBLEU and semantic similarity. spBLEU is an extension of the BLEU score that works at the sentence level, allowing for more granular evaluation of short answers. It uses n-grams to compute the overlap between the predicted and reference answers, but it's still sensitive to word order and structure, making it better suited for cases where fluency is critical. However, it's less effective for capturing meaning, which is why it's important to complement it with other metrics.
Semantic similarity offers a different approach by comparing the meanings of two sentences rather than their word structure. Using models like BERT, semantic similarity measures how close two answers are in meaning, regardless of their syntactical differences. This is useful in cases where minor rewording or synonyms are acceptable, but the limitation is that a high similarity score does not always guarantee the predicted answer is correct if precision is required.
Here is the implementation for spBLEU:
import sacrebleu
# Function to compute spBLEU score
def calculate_spBLEU(pred_answer, reference_answer, tokenize="flores101"):
# sacrebleu expects a list of references and a single hypothesis
# Here reference_answer is converted into a list for compatibility
# List of potential tokenizers:
# - "13a" for moses
# - "flores101"
# - "char" for character-based
reference_list = [reference_answer]
bleu = sacrebleu.sentence_bleu(pred_answer, reference_list, tokenize=tokenize)
return bleu.score
# Function to validate answers using spBLEU score
def validate_answer_with_spBLEU(example, pred, trace=None, threshold=10):
"""
Validate the answer by calculating the spBLEU score between predicted and example answers.
:param example: An object containing the reference answer.
:param pred: An object containing the predicted answer.
:param trace: Optional trace parameter (not used in this function).
:param threshold: The minimum spBLEU score required to consider the prediction correct.
:return: A dictionary with the spBLEU score and a correctness boolean.
"""
reference_answer = example.answer
predicted_answer = pred.answer
# Calculate the spBLEU score
spBLEU_score = calculate_spBLEU(predicted_answer, reference_answer)
# Consider the answer correct if the spBLEU score is above the threshold
is_correct = spBLEU_score >= threshold
print(f"spBLEU score: {spBLEU_score} for '{predicted_answer}' where reference is '{reference_answer}'")
return is_correctHere is the implementation for semantic similarity:
from transformers import AutoModel, AutoTokenizer
import torch
import torch.nn.functional as F
# Module-level variables to hold the tokenizer and model
_default_tokenizer = AutoTokenizer.from_pretrained(
'bert-base-uncased',
clean_up_tokenization_spaces=False
)
_default_model = AutoModel.from_pretrained('bert-base-uncased')
# Define a simple class to hold the example and predicted answers
class AnswerExample:
def __init__(self, answer):
self.answer = answer
# Function to calculate cosine similarity
def cosine_similarity(a, b):
# Compute cosine similarity along the last dimension
return F.cosine_similarity(a, b, dim=-1).mean().item()
# Function to compute BERT-like score using the transformer model
def calculate_bert_score_with_transformers(pred_answer, reference_answer,
tokenizer=_default_tokenizer,
model=_default_model):
# Encode both the predicted and reference answers
pred_input = tokenizer(pred_answer, return_tensors='pt')
ref_input = tokenizer(reference_answer, return_tensors='pt')
# Get the embeddings from the last hidden state of [CLS] token
with torch.no_grad():
pred_embedding = model(**pred_input).last_hidden_state[:, 0, :]
ref_embedding = model(**ref_input).last_hidden_state[:, 0, :]
# Calculate the cosine similarity between the two embeddings
similarity = cosine_similarity(pred_embedding, ref_embedding)
return similarity
# Function to validate answers using cosine similarity score
def validate_answer_with_cosine_similarity(example, pred, threshold=0.85,
tokenizer=_default_tokenizer,
model=_default_model):
reference_answer = example.answer
predicted_answer = pred.answer
# Calculate the cosine similarity
cosine_sim = calculate_bert_score_with_transformers(predicted_answer,
reference_answer,
tokenizer, model)
# Consider the answer correct if the similarity score is above threshold
is_correct = cosine_sim >= threshold
print(f"Cosine similarity: {cosine_sim} for '{predicted_answer}' where reference is '{reference_answer}'")
return is_correct
# Example usage
if __name__ == "__main__":
example = AnswerExample(answer="The quick brown fox jumps over the dog.")
pred = AnswerExample(answer="A fast brown fox leaps over a sleepy dog.")
result = validate_answer_with_cosine_similarity(example, pred)
print(result)After implementing the new metrics and running the evaluation for the question-answering module, it became clear that LLM-based evaluation is more effective than traditional metrics. One key issue I identified was with sentence-based BLEU, which evaluates answers by measuring n-gram overlap between the predicted and reference answers. BLEU is highly sensitive to word order and sentence length, making it prone to overvaluing syntactically similar sentences, even when the predicted answer is incorrect. While BLEU works well for tasks like translation, where fluency and structure are important, it falls short for question-answering systems, where the accuracy and correctness of the specific answer are essential.
# Evaluate the `compiled_qa` program with the `validate_answer` metric on the dev set
print(evaluate_on_dataset(compiled_qa, metric=validate_answer))
print(evaluate_on_dataset(compiled_qa, metric=validate_answer_with_spBLEU))
print(evaluate_on_dataset(compiled_qa, metric=validate_answer_with_scores))Semantic similarity, though more adept at capturing the meaning between the reference and predicted answers, also presents challenges, especially in classification tasks. For example, if the expected answer is a precise category like "book," the model might generate a related term such as "library," which would score high in semantic similarity but still be incorrect. This poses problems in tasks where exact categories or predefined answers are needed, as semantic similarity can mask these differences.
Given these limitations, the most reliable evaluation approach appears to be the "validated_answer" method, where LLM-based evaluation is used to assess the system. This method can account for context, domain-specific knowledge, and edge cases that metrics like BLEU and semantic similarity may overlook. It is more adaptable because it evaluates whether the answer fits the expectations of the domain, rather than relying on surface-level similarities or strict exact matches.
Moreover, the default metrics in DSPy, such as "exact match," are not always sufficient. While exact match works well for structured or brief answers, it struggles with more nuanced or complex responses where slight variations in wording, synonyms, or phrasing may still be correct.
In summary, for the question-answering module and similar domain-specific tasks, traditional metrics like BLEU, semantic similarity, or exact match are often insufficient. Human or LLM-based validation offers a more accurate, context-aware evaluation. It may also be beneficial to combine these methods, using semantic similarity for general understanding and fluency, alongside validated answer approaches for tasks where precision and accuracy are crucial.