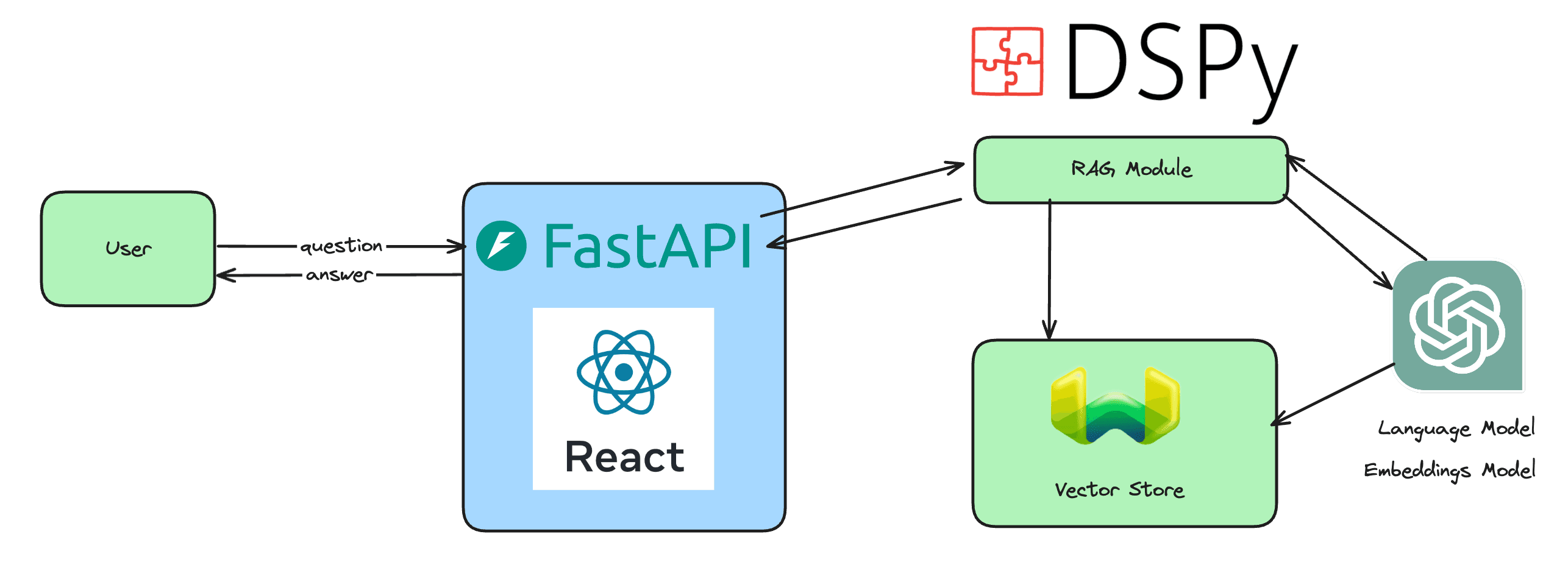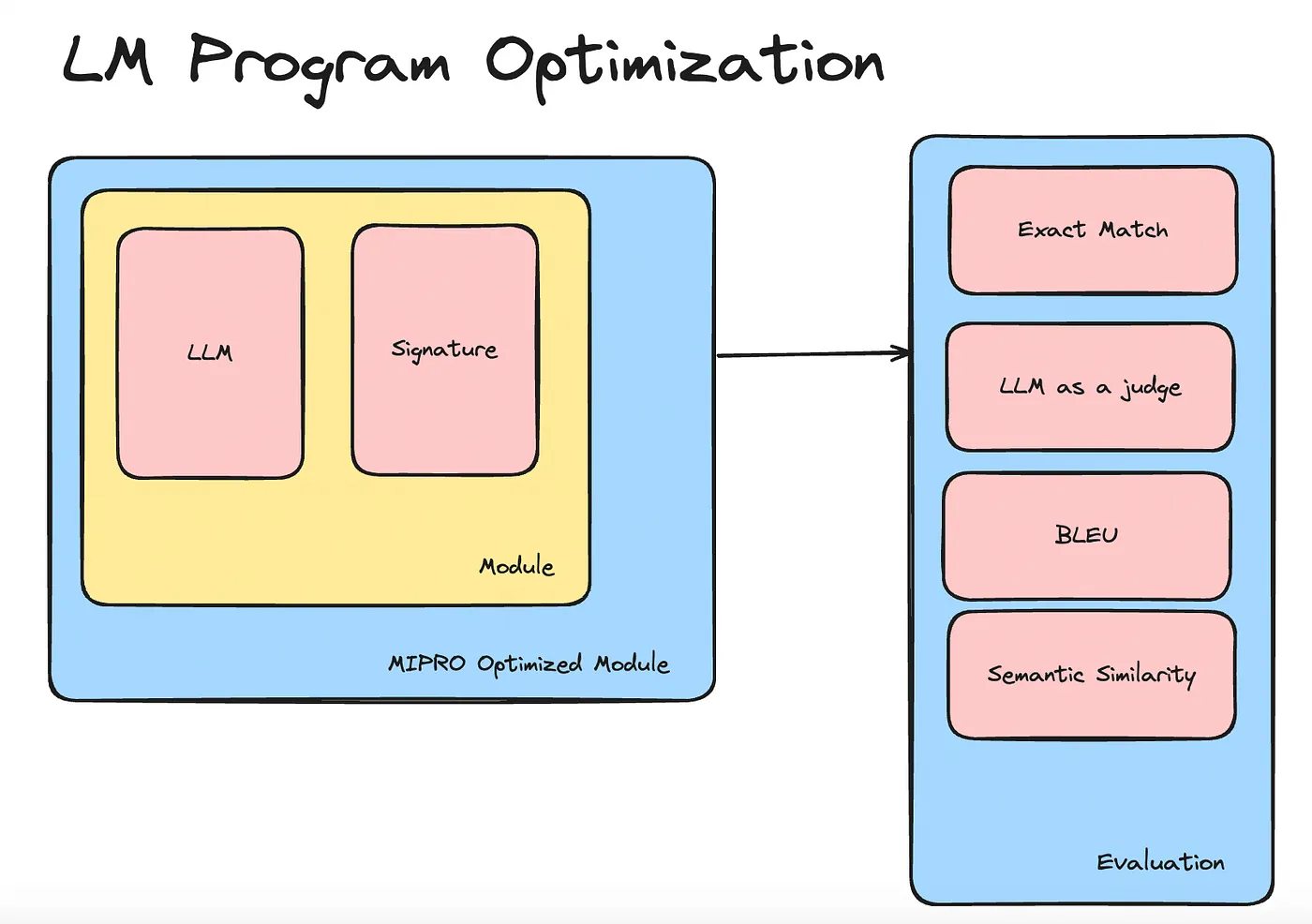
The ability to automatically optimize prompts is something that sets DSPy apart. MIPRO is a new prompt optimizer that was recently launched by the DSPy team. A few days ago, I made the decision to explore this powerful and fascinating optimizer.
In a nutshell, MIPRO allows you to optimize both the instructions and few shot examples that compose the prompt of your language module.
Here is how the optimization works. To use MIPRO, you need a dataset. For instance, for a question-answering system, you need a dataset of questions and answers. Then, you provide this dataset to the MIPRO optimizer, which uses it to infer the kind of instructions that would generate the provided answers from the provided dataset. The inference takes into account the response format, length, style, and other variables, all done automatically using another language model.
MIPRO also has a stochastic component, which generates instructions, selects few-shot examples, and evaluates the system. To evaluate the module’s performance, a metric needs to be specified every time you create a MIPRO optimizer. MIPRO ensures that this metric is optimal by measuring it through every iteration and sustaining the optimization loop until it gets to the optimal value. Ideally, the metric should increase to 100%, but it may stop at 90%, for example. That’s the general workflow.
Let me give you an example of how to implement this. In my script, I make use of the Aya Collection dataset from Cohere, which is accessible on Hugging Face.
The Aya Collection is a multilingual dataset used to train open-source models from the Aya series. It’s an extremely useful open-source dataset.
The first step in the script is to define the language model that I will use. GPT-4o from OpenAI is the choice in this instance.
from datasets import load_dataset
import dspy
from dspy.teleprompt import MIPROv2 as MIPRO
from dspy.functional import TypedPredictor
from dspy.evaluate.evaluate import Evaluate
import os
from dotenv import load_dotenv
load_dotenv()
llm = dspy.OpenAI(
model='gpt-4o',
api_key=os.environ['OPENAI_API_KEY']
)
dspy.settings.configure(lm=llm)Next, I load data from the Aya Collection, and in this case, I only consider the data from the Mintaka template, which is a subset of the Aya Collection. I use both the training and validation splits for the training and validation sets, respectively.
train = load_dataset("CohereForAI/aya_collection", "templated_mintaka", split="train")
dev = load_dataset("CohereForAI/aya_collection", "templated_mintaka", split="validation")I then perform repetitive steps, such as filtering the data to keep only English entries (since the dataset is multilingual), formatting the dataset (it’s a question-answer dataset), and preparing each dataset item as a DSPy example. Following this, I define the input (the question) and the expected outcome (the answer). All of this is crucial for the optimization process.
# get the subset of the dataset where 'language': 'eng'
trainset = train.filter(lambda x: x['language'] == 'eng')
devset = dev.filter(lambda x: x['language'] == 'eng')
trainset = [dspy.Example({'question': x['inputs'], 'answer': x['targets']}) for x in trainset]
devset = [dspy.Example({'question': x['inputs'], 'answer': x['targets']}) for x in devset]
trainset = [x.with_inputs('question') for x in trainset]
devset = [x.with_inputs('question') for x in devset]I then take a subset of 10 examples from the training set and the dev set, as MIPRO optimization consumes many tokens and can become expensive, especially when using OpenAI models via API.
I also defined and commented out a function process_dataset to streamline the repetitive data processing steps applied so far.
# keep only the first 10 examples for now train and dev sets
trainset = trainset[:10]
devset = devset[:10]
# # Define a function to process datasets
# def process_dataset(dataset, language='eng', max_examples=10):
# # Filter the dataset by language
# subset = dataset.filter(lambda x: x['language'] == language)
# # Transform the dataset to the desired format
# examples = [dspy.Example({'question': x['inputs'], 'answer': x['targets']}) for x in subset]
# # Set inputs to 'question'
# examples = [x.with_inputs('question') for x in examples]
# # Return only the first 'max_examples' examples
# return examples[:max_examples]
# # Apply the function to both train and dev datasets
# trainset = process_dataset(train)
# devset = process_dataset(dev)Now that we have the data fully prepared, I create the generateAnswer signature, which tells DSPy that a question will be the input and generating an appropriate answer is the expected behaviour. Then I define the AnswerEval signature, which is crucial because I will use another language model to evaluate whether the predicted answers match the reference answers.
class GenerateAnswer(dspy.Signature):
"""Answer questions in a simple and succinct manner."""
question = dspy.InputField()
answer = dspy.OutputField(desc="answer to the question")
class AnswerEval(dspy.Signature):
"""Evaluate if the predicted answer and the true answer are in accordance."""
pred_answer = dspy.InputField(desc="predicted answer")
answer = dspy.InputField(desc="true answer")
correct: bool = dspy.OutputField(desc="whether the predicted answer is correct True/False")I then build a simple Question Answering (QA) module using the GenerateAnswer signature. I validate the answers generated by the module using another language model call. To achieve this, a Typed Predictor from DSPY is required. Using the AnswerEval signature, the Typed Predictor will return a boolean value (True if the predicted answer and the reference answer are in agreement, and False if not).
class QA(dspy.Module):
def __init__(self):
super().__init__()
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
prediction = self.generate_answer(question=question)
return dspy.Prediction(answer=prediction.answer)
# Function to check if the answer is correct
def validate_answer(example, pred, trace=None):
# use the LM to check if the answer is correct
answer_checker = TypedPredictor(AnswerEval)
return answer_checker(pred_answer=pred.answer, answer=example.answer).correctI define the MIPRO optimizer, specifying the language model for optimizing instructions and prompts, as well as the evaluation metric (validate_answer). Compiling the MIPRO optimizer results in the creation of an optimized Question Answering module (compiled_qa).
# Set up a basic optimizer, which will compile our RAG program.
optimizer = MIPRO(prompt_model=llm, task_model=llm, metric=validate_answer)
# Compile!
compiled_qa = optimizer.compile(QA(),
trainset=trainset,
max_bootstrapped_demos=3,
max_labeled_demos=1,
eval_kwargs={})Finally, I evaluate the compiled QA and it indeed provides better answers. The accuracy is around 40–50% without optimization, but it increases to 50–60% with optimization, depending on the model used. Overall, performance increases with optimization.
# Evaluate on the dev set
# Set up the evaluator
evaluate_on_dataset = Evaluate(devset=devset,
num_threads=1,
display_progress=True,
display_table=5)
# Evaluate the `compiled_qa` program with the `validate_answer` metric on the dev set
print(evaluate_on_dataset(compiled_qa, metric=validate_answer))In conclusion, using DSPy and particularly the MIPRO optimizer is a good way to improve the robustness of your language programs, provided you have access to a dataset that fits the input/output pairs your language programs are supposed to generate. Although it’s expensive, especially with large data sets, it could be worth it in most circumstances.