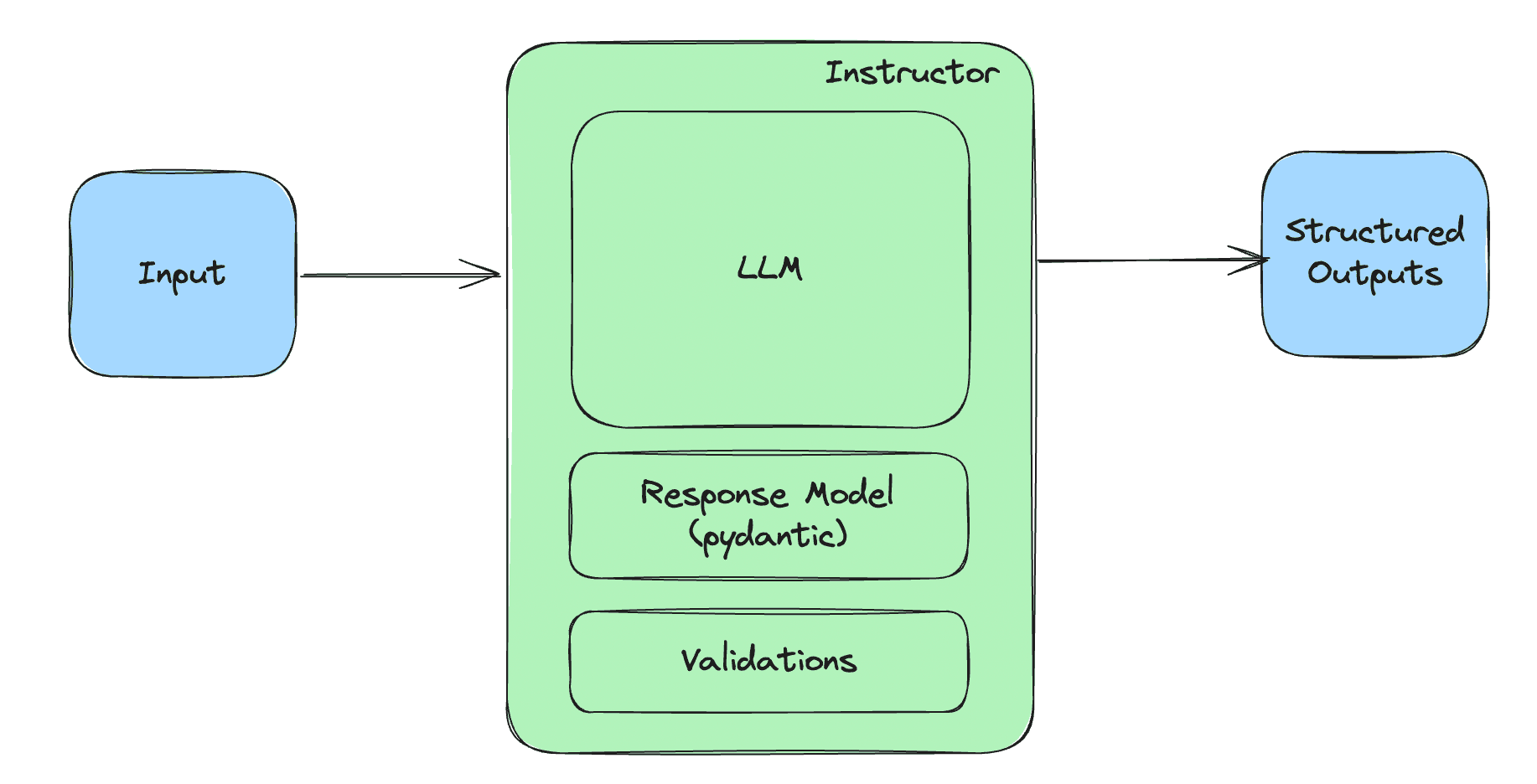
Building robust LLM-based applications is token-intensive. You often have to plan for the parsing and digestion of a lot of tokens for summarization or even retrieval augmented generation. Even the mere generation of marketing blogposts consumes a lot of output tokens in most cases. Not to mention that all robust cognitive architectures often rely on the generation of several samples for each prompt, custom retry logics, feedback loops, and reasoning tokens to achieve state of the art performance, all solutions powerfully token-intensive.
Luckily, the cost of intelligence is quickly dropping. GPT-4, one of OpenAI’s most capable models, is now priced at $2.5 per million input tokens and $10 per million output tokens. At its initial release in March 2023, the cost was respectively $10/1M input tokens and $30/1M for output tokens. That’s a huge $7.5/1M input tokens and $20/1M output tokens reduction in price.
Impressive, right? There is something even cheaper!
Thanks to open source, you can access powerful models at an even lower price. Nebius AI, a European AI infrastructure company, recently launched the Nebius AI studio. It allows AI engineers to easily access open-source large language models without having to go through the hassle of setting up an inference server. On Nebius, you can access open-source models released by Mistral, Qwen, Microsoft, or Meta (the Llama suite of models).
You can literally get performance on par with GPT-4 by simply using Meta-Llama-3.1–405B on Nebius AI Studio, and it is insanely cheap ($1/1M input tokens vs $2.5 for GPT-4, and $3/1M output tokens vs $10 for GPT-4).
Using open-source models via the Nebius AI Studio is very simple. You just have to create your account at https://nebius.com/studio/inference . You get $100 dollars of free credits to start experimenting. And for the API, nothing simpler. Once you create an API key, you can start using the models via a client you are no doubt already familiar with: the Python OpenAI client.
Here is an example:
import os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(
base_url="https://api.studio.nebius.ai/v1/",
api_key=os.environ.get("NEBIUS_API_KEY"),
)
completion = client.chat.completions.create(
model="meta-llama/Meta-Llama-3.1-70B-Instruct",
messages=[
{
"role": "user",
"content": """Write an article about the benefits of exercise."""
}
],
temperature=0.6
)
print(completion.choices[0].message.content)Now, let’s get our hands dirty and see all the amazing things you can do with the Nebius AI Studio.
Like previously stated, achieving GPT-4 level performance at a fraction of the cost using Nebius AI studio is pretty easy. You just have to use Llama 3.1–405B because the performance improvement is already baked in the base model. To refresh your memory, here is a look at the benchmarks:
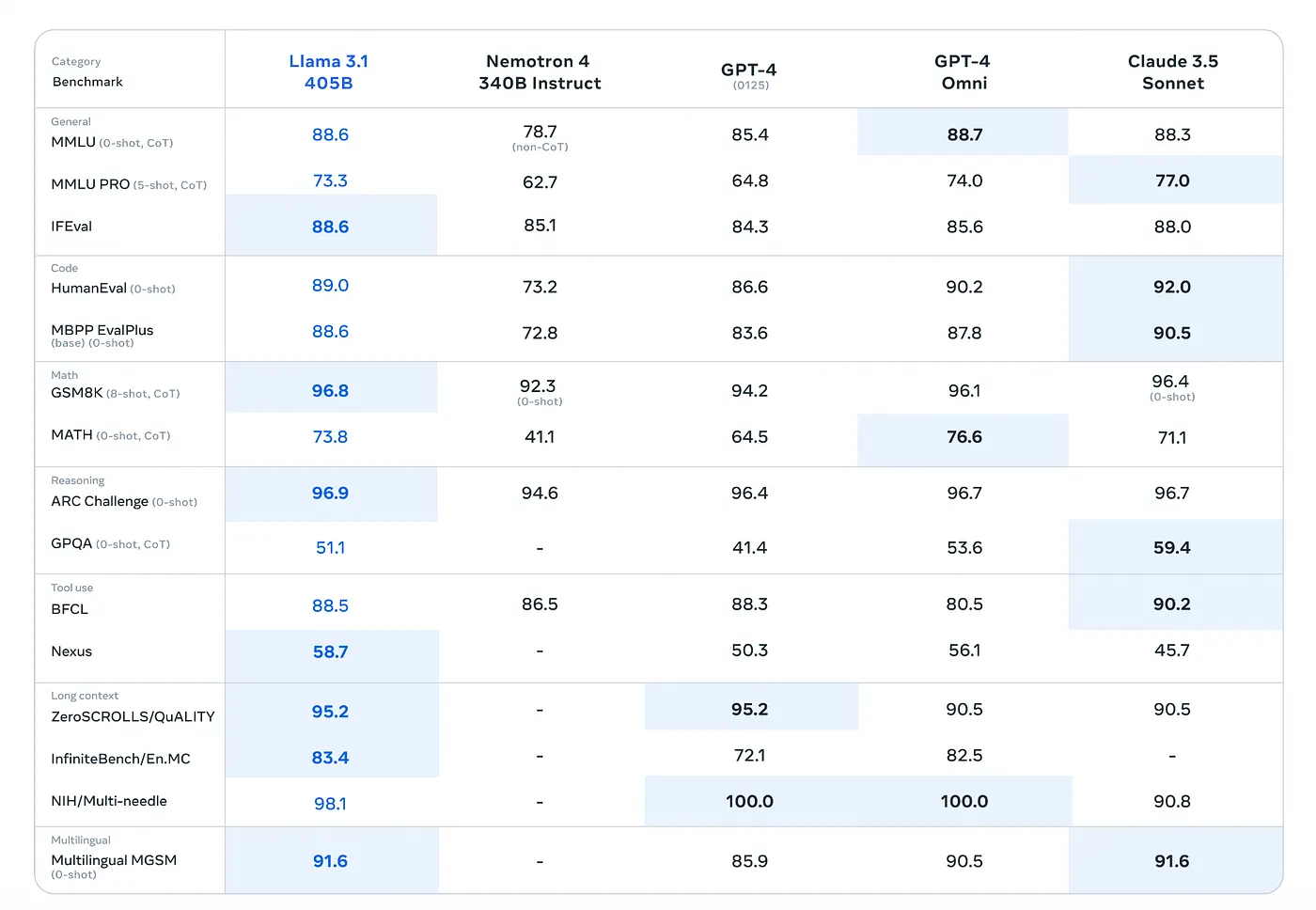
The impressive performance of Llama 3.1 405B
As you can see, Llama-3.1–405B beats GPT-4 on most benchmarks.
Let’s go a step further. What if you want to mimic the performance of o1 preview, OpenAI’s most powerful model using Llama-3.1–405B? Let’s see how you could do that.
o1 preview is what Prof. Subbarao Kambhampati calls LRMs (Large Reasoning Models), the first of its kind. Its specific training allows it to achieve better performance for tasks that require reasoning (math, code, PhD-level science questions for example). But this comes with a huge caveat. Using o1 preview is costly. Input tokens are priced at $15/1M tokens and output tokens at $60/1M.
Keep in mind that output tokens include reasoning tokens, so you can end up with a fat API bill quite rapidly. We wouldn’t want that, would we ?
So, let’s see how you can build your own custom large reasoning model that mimics o1 preview and can achieve similar performance at a fraction of the cost. Here are three key abstractions to keep in mind for the custom LRM you are going to build.
-Model: This is the open-source model from Nebius AI Studio that you are going to use. In this case, it will be the best Llama-3.1 model, which is the Llama-3.1–405B.
-Memory: This component will help you manage conversation history seamlessly with automatic sliding context and smart retrieval strategies.
-Reasoning Procedure: This component is the key because it will allow you to customize how you want your LRM to reason over problems. To mimic o1 preview, your LRM will first think step by step (execute each thinking step, then gather the results to craft a final answer).
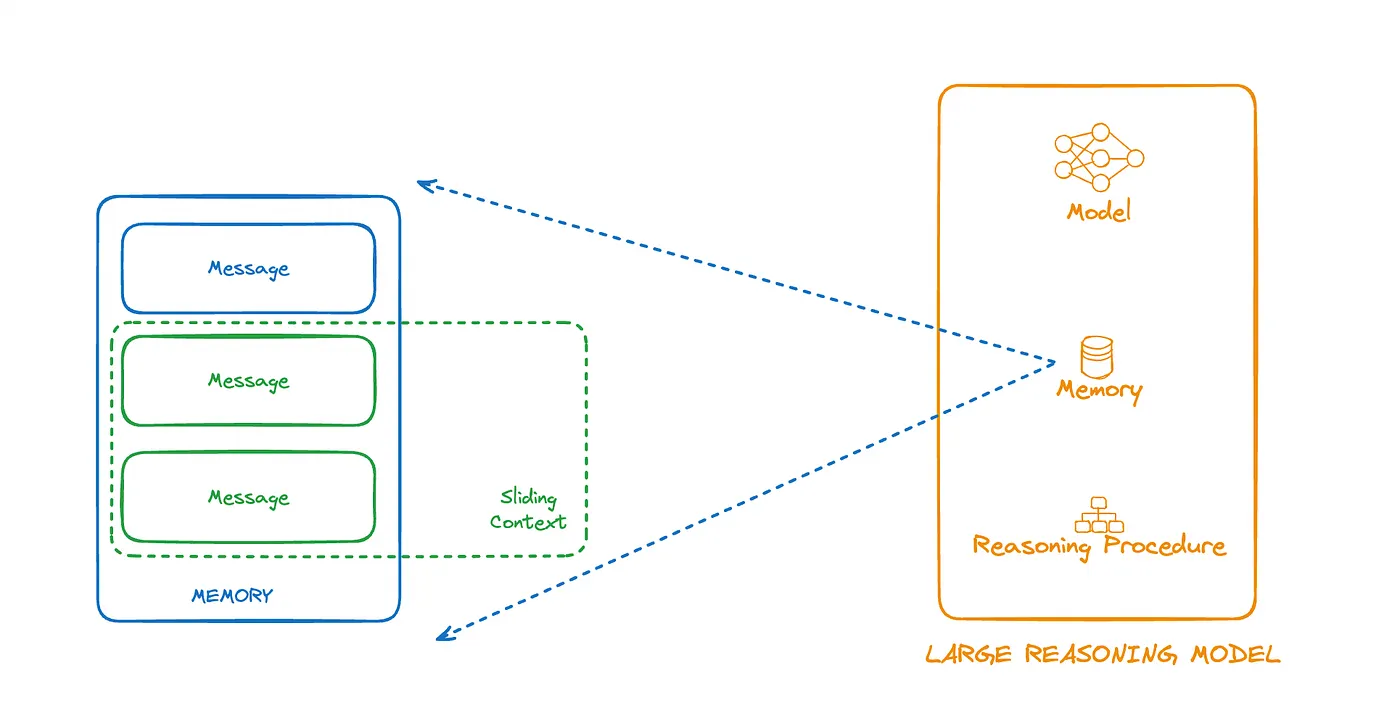
Anatomy of a Large Reasoning Model
Now let’s go through the implementation in Python. First, you have to define a Message class.
The Message class is the basic unit of your architecture. It is defined by a role and a content to allow us to interact with large language models (using the Nebius AI Studio API). A message can also be truncated if context length requirements impose it. Consequently, the message class contains the logic of how that will be done. You will also need to define the three types of prompts needed(system, steps, and answer prompts) as constants.
import os
import re
from dotenv import load_dotenv
from colorama import init, Fore, Style
# Initialize colorama
init(autoreset=True)
# Load environment variables
load_dotenv()
# Constants for prompts
SYSTEM_PROMPT = """
You are a large reasoning model. You are given a question and you need
to reason step by step to find the answer. Do not provide the answer unless
you have reasoned through the question.
You can use Python code and write it in <python> and </python> tags.
The Python code could help you solve some of the steps.
Write it in a way that it can be parsed and executed using the exec() function.
Only use Python standard libraries.
Add explicit print statements so the output could be explained easily.
Only use Python code if it is absolutely necessary.
Be mutually exclusive and collectively exhaustive in your reasoning.
"""
STEPS_PROMPT = """
First, I need to think about the question and the thinking steps I need to take.
Put those steps into an opening <thinking> and closing </thinking> tag.
Each step should be in a <step> tag.
Example: steps to check if a number is prime:
<thinking>
<step>Check if the number is greater than 1.</step>
<step>Check if the number is divisible by any number other than 1 and itself.</step>
</thinking>
Do not provide an answer yet.
"""
ANSWER_PROMPT = """
Now I will use the thinking steps to reason and craft the complete final answer.
The answer should contain all the logical steps I took to arrive
at the answer.
Put the answer in an opening <answer> and closing </answer> tag.
Example: <answer>The number is prime because it is greater than 1 and
not divisible by any number other than 1 and itself.</answer>
"""
class Message:
"""Represents a message in the conversation."""
def __init__(self, role, content):
self.role = role
self.content = content
def to_dict(self):
return {"role": self.role, "content": self.content}
def truncate(self, max_tokens=200, mode: str = "start"):
tokens = self.content.split()
if len(tokens) > max_tokens:
if mode == "start":
self.content = " ".join(tokens[:max_tokens])
elif mode == "end":
self.content = " ".join(tokens[-max_tokens:])
elif mode == "mix":
self.content = " ".join(tokens[:max_tokens // 2] + tokens[-max_tokens // 2:])
elif mode == "random":
import random
self.content = " ".join(random.sample(tokens, max_tokens))
self.content += "..."
return selfNext, you need to define the Memory class. The memory is a data structure that will help you keep a history of messages and manage the context of chat completions.
class Memory:
"""Manages the conversation history and context."""
def __init__(self, context_length=200):
self.context_length = int(context_length * 0.9) # Apply a 10% buffer
self.history = []
def add_message(self, message: Message):
"""Adds a message to the conversation history and prints the updated history."""
self.history.append(message.to_dict())
self.pretty_print_history()
self._update_context()
def _update_context(self):
total_length = sum(len(msg["content"].split()) for msg in self.history)
if total_length <= self.context_length:
return
# Truncate messages from the start except for system messages
new_history = []
remaining_length = self.context_length
for message in reversed(self.history):
msg_length = len(message["content"].split())
if message["role"] == "system" or remaining_length - msg_length >= 0:
new_history.insert(0, message)
remaining_length -= msg_length
else:
break
self.history = new_history
def pretty_print_history(self):
"""Prints the last message in the conversation history in a readable format with colors."""
if not self.history:
return # No messages to print
msg = self.history[-1] # Get the last message
role = msg['role']
content = msg['content']
if role == 'system':
color = Fore.YELLOW + Style.BRIGHT
elif role == 'user':
color = Fore.GREEN + Style.BRIGHT
elif role == 'assistant':
color = Fore.CYAN + Style.BRIGHT
else:
color = Style.RESET_ALL
print(f"{color}Role: {role}{Style.RESET_ALL}")
print(f"{color}Content:\n{content}{Style.RESET_ALL}")
print(f"{'-' * 100}\n")
def clear(self):
self.history = []Finally, you can define your Large Reasoning Model. It will combine a large language model (Llama-3.1–405B), a memory, and a reasoning procedure. In this case, the latter involves the creation of thinking steps before solving a problem and the use and execution of Python code when necessary. After executing each step, the LRM then gathers all the information to produce an answer.
class LargeReasoningModel:
"""Simulates a large reasoning model that processes instructions step by step."""
def __init__(self, model_name="meta-llama/Meta-Llama-3.1-405B-Instruct", context_length=128000):
self.model_name = model_name
self.context_length = context_length
self.memory = Memory(context_length=self.context_length)
self.client = self._initialize_client()
self.memory.add_message(Message(role="system", content=SYSTEM_PROMPT))
def _initialize_client(self):
"""Initializes the API client."""
from openai import OpenAI
return OpenAI(
base_url="https://api.studio.nebius.ai/v1/",
api_key=os.environ.get("NEBIUS_API_KEY"),
)
def generate_response(self, messages, temperature=0.6, logprobs=False):
"""Generates a response from the model."""
completion = self.client.chat.completions.create(
model=self.model_name,
messages=messages,
temperature=temperature,
logprobs=logprobs
)
return completion.choices[0].message
@staticmethod
def extract_python_code(response_content):
"""Extracts Python code enclosed in <python> tags."""
pattern = re.compile(r'<python>(.*?)</python>', re.DOTALL)
match = pattern.search(response_content)
if match:
return match.group(1).strip()
return None
@staticmethod
def extract_steps(response_content):
"""Extracts Python code enclosed in <step> tags."""
pattern = re.compile(r'<step>(.*?)</step>', re.DOTALL)
match = pattern.search(response_content)
if match:
# Extract all steps and return as a list
steps = pattern.findall(response_content)
return steps
return None
@staticmethod
def execute_python_code(code):
"""Executes Python code and returns the output."""
try:
# Preload necessary modules
import io
import contextlib
import math
import random
# Create an isolated global environment for exec
exec_globals = {
'__builtins__': __import__('builtins'), # Allow basic built-ins
'math': math, # Allow math functions
'random': random, # Allow random functions
}
local_vars = {}
# Capture output
with io.StringIO() as buf, contextlib.redirect_stdout(buf):
exec(code, exec_globals, local_vars)
output = buf.getvalue()
return f"The following Python code was executed successfully:\n{code}\nOutput:\n{output}"
except ImportError as imp_err:
return f"ImportError occurred: {str(imp_err)}"
except Exception:
import traceback
return f"An error occurred while executing the code:\n{traceback.format_exc()}"
def reasoning(self, instruction, temperature=0.2, logprobs=False, max_retries=5):
"""Performs step-by-step reasoning based on the instruction."""
self.memory.add_message(Message(role="user", content=instruction))
self.memory.add_message(Message(role="assistant", content=STEPS_PROMPT))
# Attempt to parse the assistant's response
for _ in range(max_retries):
response = self.generate_response(self.memory.history, temperature=temperature, logprobs=logprobs)
try:
steps = self.extract_steps(response.content)
break
except Exception:
continue
else:
raise ValueError("Failed to parse steps from the assistant's response.")
self.memory.add_message(Message(role="assistant", content=response.content))
max_retries = 3 # Define the maximum number of retries
for i, step in enumerate(steps, 1):
step_message = f"Let's do step {i}: {step}"
self.memory.add_message(Message(role="assistant", content=step_message))
response = self.generate_response(self.memory.history, temperature=temperature, logprobs=logprobs)
self.memory.add_message(Message(role="assistant", content=response.content))
# Extract and execute any Python code in the response
python_code = self.extract_python_code(response.content)
if python_code:
retries = 0
success = False
while retries < max_retries and not success:
python_output = self.execute_python_code(python_code)
# Check for errors in the output
if "error" in python_output.lower():
# If error, add error message
error_message = f"An error occurred while executing step {i}: {python_output}"
self.memory.add_message(Message(role="assistant", content=error_message))
# Retry message
retry_message = f"Retrying step {i} to ensure no further errors (Attempt {retries + 1} of {max_retries})"
self.memory.add_message(Message(role="assistant", content=retry_message))
retries += 1
else:
# If successful, proceed
self.memory.add_message(Message(role="assistant", content=python_output))
success = True
if not success:
final_error_message = f"Step {i} encountered errors after {max_retries} retries. Moving on to the next step."
self.memory.add_message(Message(role="assistant", content=final_error_message))
# Ask for the final answer
self.memory.add_message(Message(role="assistant", content=ANSWER_PROMPT))
final_response = self.generate_response(self.memory.history, temperature=temperature, logprobs=logprobs)
self.memory.add_message(Message(role="assistant", content=final_response.content))
return final_response.content
if __name__ == "__main__":
# Example usage
model = LargeReasoningModel()
# response = model.reasoning("Is 1253 a prime number?")
response = model.reasoning("is 125849302233 a prime ?")
print(f"{Fore.BLUE + Style.BRIGHT}Final Answer:{Style.RESET_ALL}")
print(response)Here is a demo:

The LRM in action !
Awesome, right? You have just scratched the surface of what is possible thanks to the Nebius AI Studio, and at an impressively cheap price. To start experimenting, just create an account at https://nebius.com/studio/inference and take advantage of the $100 dollars of free credit offered.
Happy coding !